CSC 523 - Advanced Scripting for Data Science, Fall
2024, Tuesday 6:00-8:50 PM, Old Main 158.
Assignment 1 Specification, code is due by end of
Friday September 20. via make turnitin on acad or
K120023GEMS. Perform the
following steps on K120023GEMS.kutztown.edu
after
logging into your account via putty or ssh,
after doing your initial
setup for the new Linux server K120023GEMS:
cd
# places you into your login directory mkdir DataMine
# all of your csc523 projects
go into this directory cd ./DataMine
# makes DataMine
your current working directory, it may already exist cp
~parson/DataMine/CSC523f24ClassifyAssn1.problem.zip
CSC523f24ClassifyAssn1.problem.zip unzip CSC523f24ClassifyAssn1.problem.zip
# unzips your working copy of the project directory cd ./CSC523f24ClassifyAssn1
#
your project working directory
Perform all test execution on K120023GEMS.kutztown.edu to
avoid any platform-dependent output differences.
All input and output CSV data files in Assignment 1 reside in
~parson/DataMine.
The project makefile uses symbolic links to give you access;
notepad++ does not follow symbolic links.
Here are the files of interest in this project directory.
There are a few you can ignore. Make
sure to answer README.txt in your project
directory. A missing README.txt incurs a
late charge.
Here is an add on 9/23 for why K-Nearest_Neighbor with
number-of-neighbors = 5 does poorly.
It really has to do with an inadequate number of training
instances
for 5 class values contained in only 10 training instances. Once
you
get past KNN=2, you would have inaccurate results even in a
balanced
training distribution of 2 target classes each. This training
set is
even worse. See my answer below.
CSC523f24ClassifyAssn1_generator.py # your work goes here,
analyzing correlation coefficients and kappa for
regressors
& classifiers
CSC523f24ClassifyAssn1_main.py #
Parson's handout code for building & testing
models that your generator above provides makefile
# the Linux make utility uses this script to direct testing
& data viz graphing actions Sept 4 add: Please
edit the makefile per these instructions.
makelib
# my library for
the makefile CSC523F24Assn1Handout.csv.gz is the input data file linked from
~parson/DataMine when you enter make test
or make links.
To unzip CSC523F24Assn1Handout.csv.gz: make clean links cp
CSC523F24Assn1Handout.csv.gz junk.csv.gz gunzip
junk.csv.gz
You can now inspect junk.csv.
A subsequent make test, make clean, or
make turnitin will remove any junk* file.
Here is sample of the 5000 input data instances (rows)
that we will split into 2500 training and 2500 testing
instances.
Links go to the first of 1000 instance illustrations
from CSC558 Assignment 1. We are using the same data in
CSV format.
The job of your models is to predict the target (a.k.a.
class) value of the Distribution from the set
{uniform, normal, bimodal, exponential, revexponential} based on
correlations with subsets of
the other, non-target attributes.
The coding details are in file CSC523f24ClassifyAssn1_generator.py
in the handout directory.
$ make student
grep 'STUDENT *[1-9]'
CSC523f24ClassifyAssn1_generator.py
# STUDENT 1 (1%): Complete the above comment block. Fill
in the blanks.
# STUDENT 2 (4%) Read and extract
CSC523F24Assn1Student.csv.
# STUDENT 3 (15%) Extract and save
CSC523F24Assn1MinAttrs.csv:
# STUDENT 4 (10%): Select the first
10 instances of minAttrsData:
# STUDENT 5 (10%): Construct 8
Classifier objects (1.25% each) spec'd below.
# STUDENT 5a. Construct two
DecisionTreeClassifier, one assigned into
# STUDENT 5b. Construct a
GaussianNB() classifier with its defaul parameters,
# STUDENT 5c. Construct two
KNeighborsClassifier objects,
Detailed instructions follow each of those. When coding
is completed, make clean test tests the code,
giving this answer at the end when everything works:
TESTS PASS. Make sure to complete README.txt before make
turnitin.
The following error indicates that you are not logged
into ssh K120023GEMS.kutztown.edu for testing:
Traceback (most recent call last):
File "CSC523f24ClassifyAssn1_main.py", line 31,
in <module>
from sklearn.tree import export_text
# These 3 needed for printing trees
ImportError: cannot import name 'export_text' from
'sklearn.tree' (/opt/anaconda
3/lib/python3.7/site-packages/sklearn/tree/__init__.py)
make: *** [test] Error 1
If there is a difference between the program's output
file and an expected reference file (.ref),
the Linux diff utility reports a difference and leaves
the details in a .dif file. We will go over how
to interpret these files.
You can edit answers into README.txt before or
after completing make test, although coding
informs some of the answers. Please take notes in class.
I will go over a lot of how this
project infrastructure interacts with Python libraries
including scikit-learn
for building and testing models.
When one final make clean test passes and you
have answered all questions in README.txt,
run command line make turnitin (NOT the turnin
script used in some other courses) and hit Enter
when prompted. If make turnitin does not report
an error, I have received your project. You will
not receive an email.
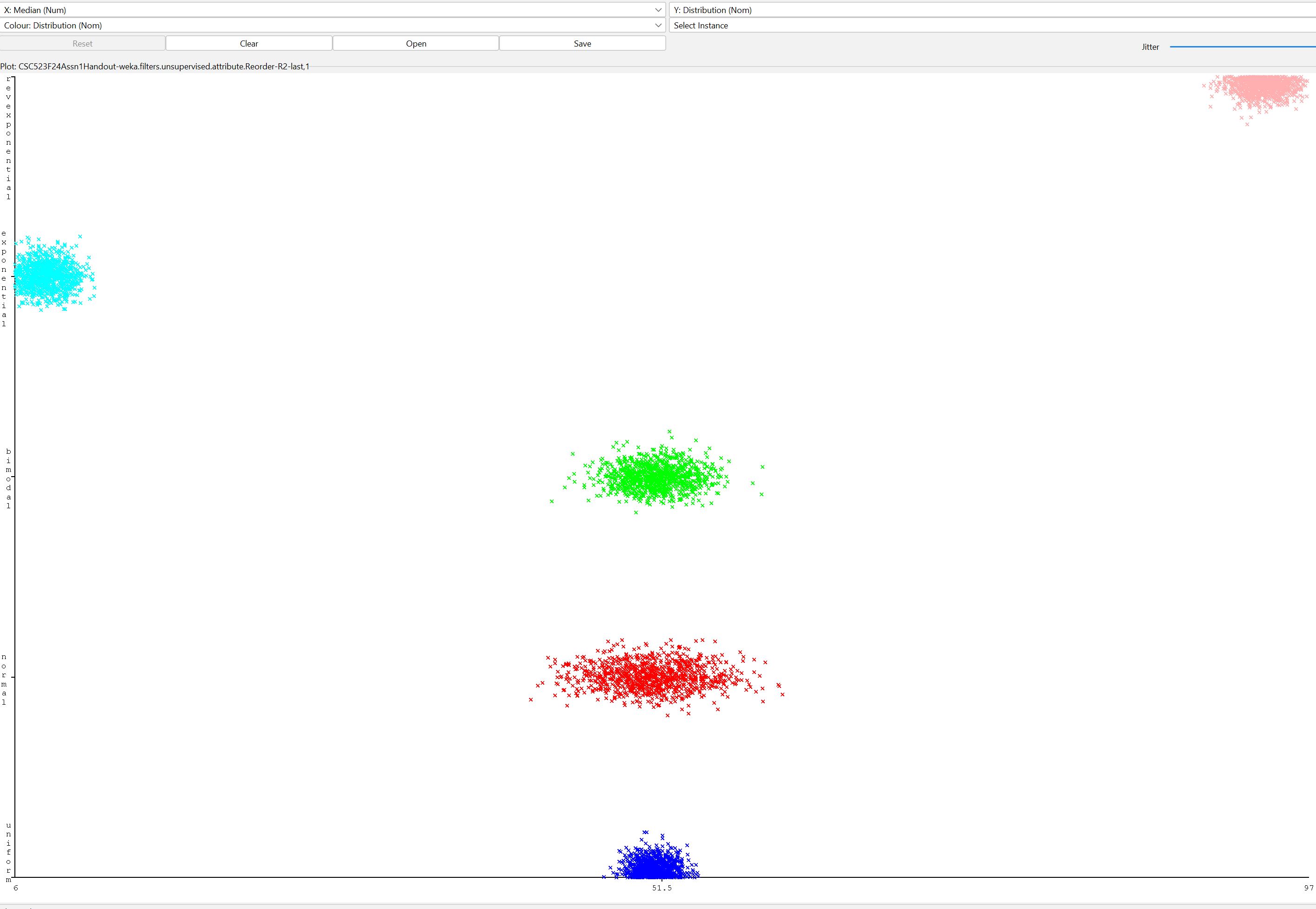
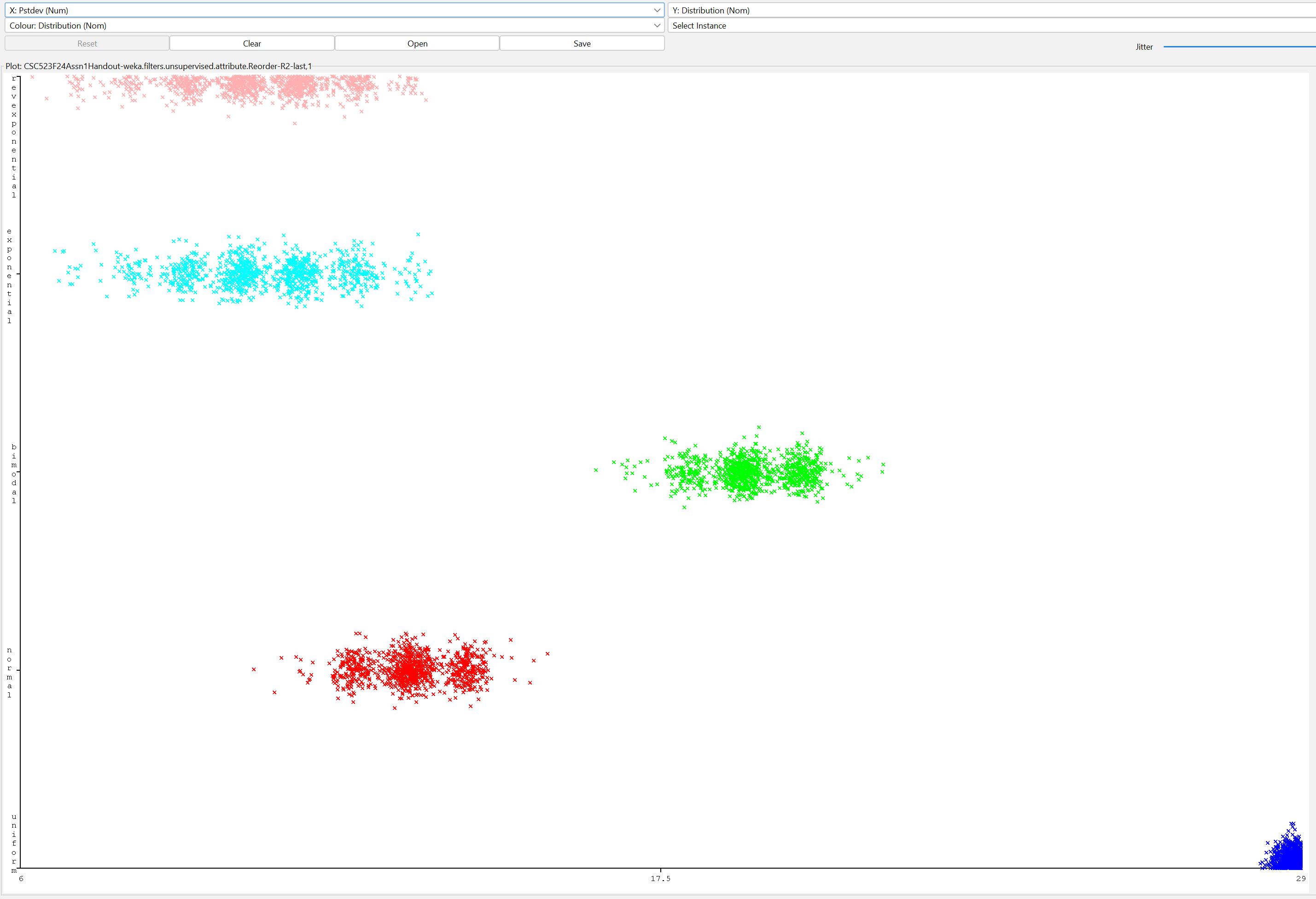
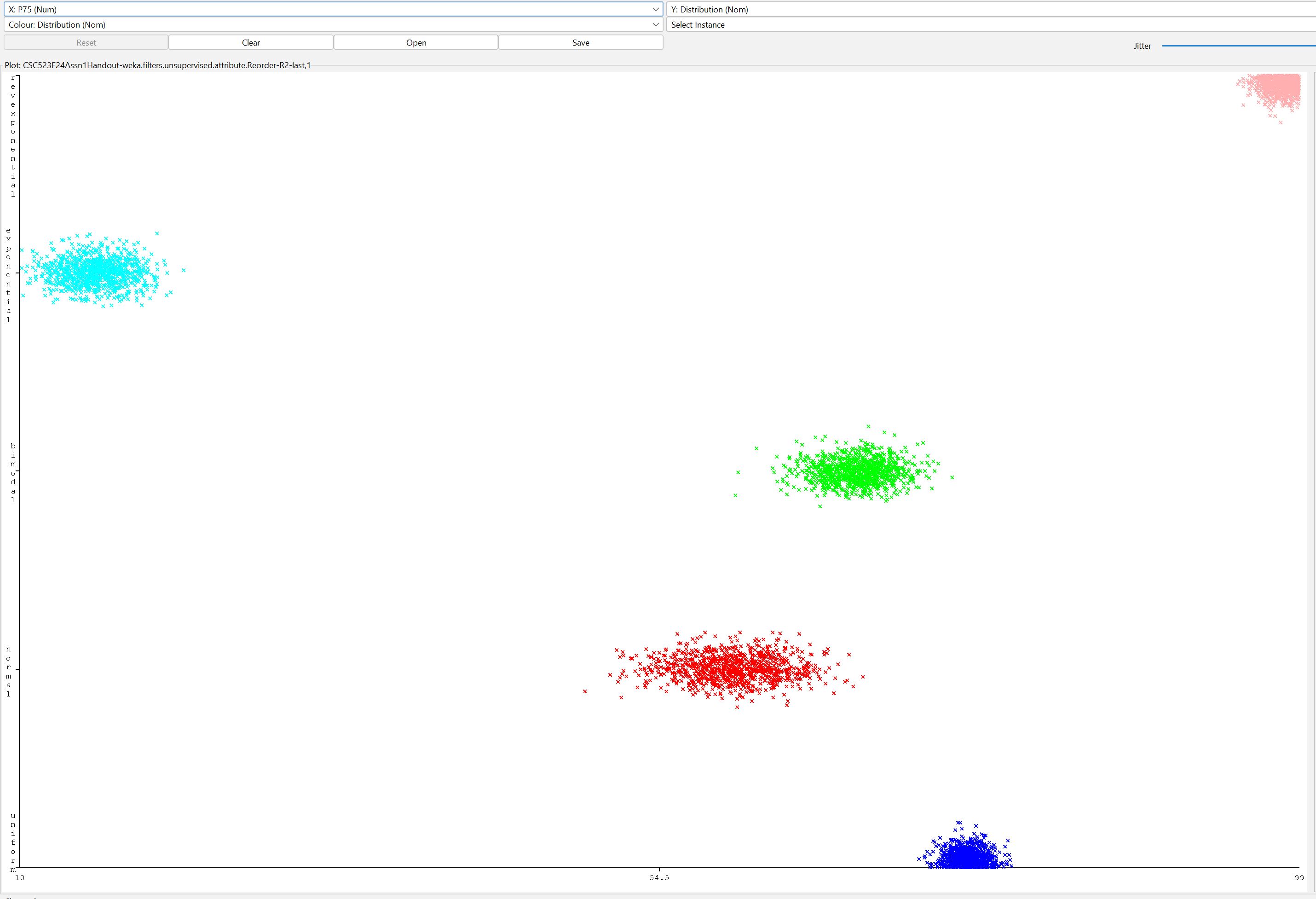
Here are some Weka scatter plots pulled from your input
data file CSC523F24Assn1Handout.csv.gz.
These relate to several questions in README.txt
Figure 1: Distribution class values as a function of
Median
Figure 2: Distribution class values as a function of
Pstdev
Figure 3: Distribution class values as a function of
P75 (75th percentile of data)