CSC 458 - Data
Mining & Predictive Analytics I, Spring 2024.
Confusion Matrix Confusion for ZeroR Confusion Matrices.
In the
February 7 class all of us including the instructor were
confused why ZeroR on 5 equal-size classes
(2001 instances each) would distributed predictions across
more than one class. Documentation says that
ZeroR selects the mean of the target attribute
values for (numeric target) regression and the statistical mode
for classification. There is no unique mode when two or more
categories tie for biggest class.
I figured it out after class by
playing with Weka. Docs and on-line docs were useless.
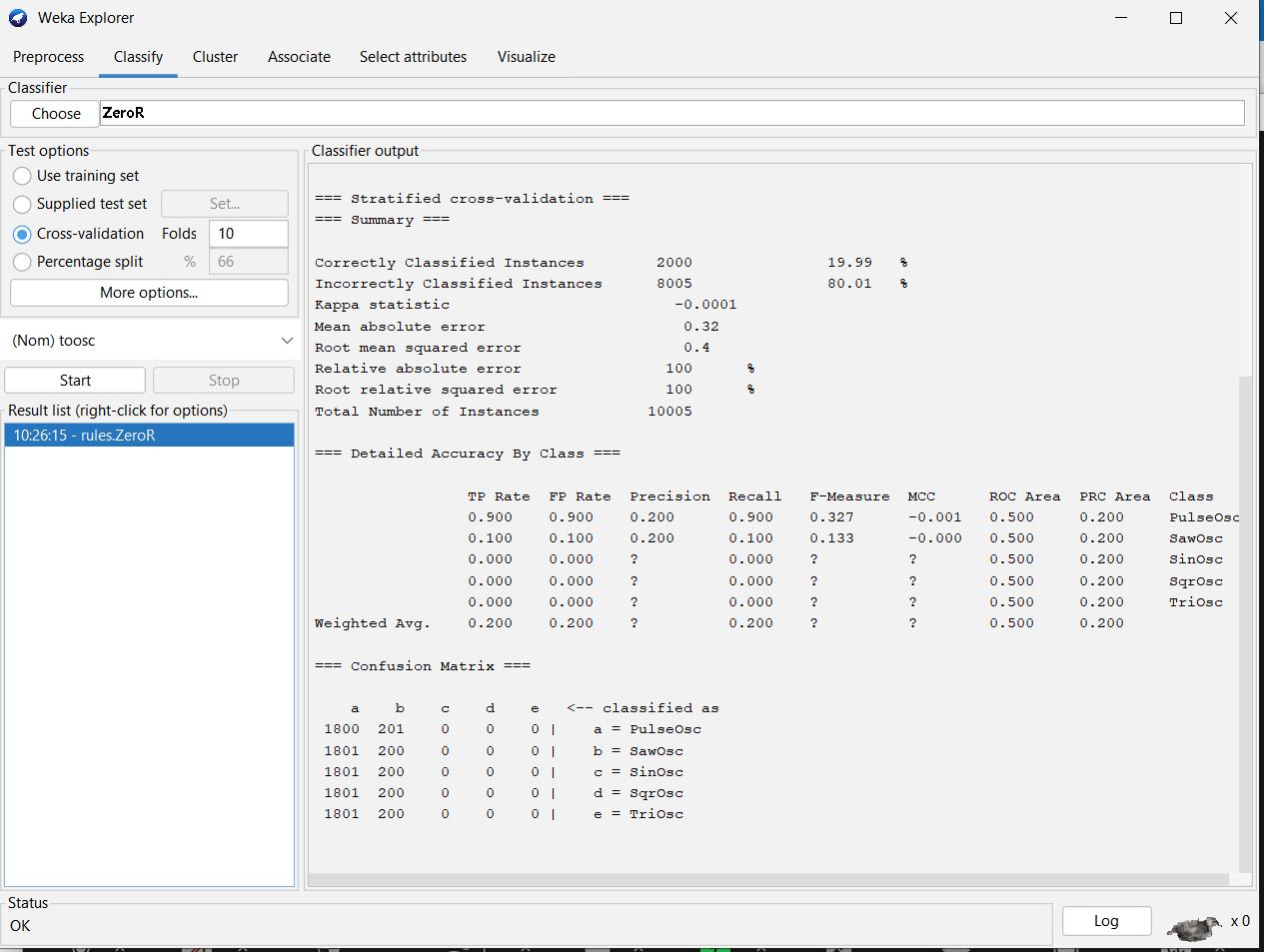
A Confusing ZeroR Confusion Matrix for 10-fold
Cross-validation
It has to do with 10-fold cross validation. In
10-fold cross-validation Weka takes 9/10ths
of the instances randomly for training and 1/10th for
testing. It does this 10 times with different
instances used for testing each round. It then adds an extra round
of training and testing on
the entire dataset (see
slides 23-27 of textbook's author on cross-validation).
There are 10,005/10 = 1000 or 1001 testing instances per round. On
one of those rounds,
ZeroR classified 1001 as sawOsc in the above confusion matrix. In
the other 9 rounds, ZeroR
classified them as PulseOsc. The rounds are statistically
independent from each other, which
is why the tie-for-mode becomes random selection for a bin each
round. There is possibly
some statistical bias in ZeroR that acounts for piling up in
PulseOsc, but that piling up is
possible with a randomly selected bin on each round.
The remaining illustrations show other N-fold cross-validation
runs of ZeroR.
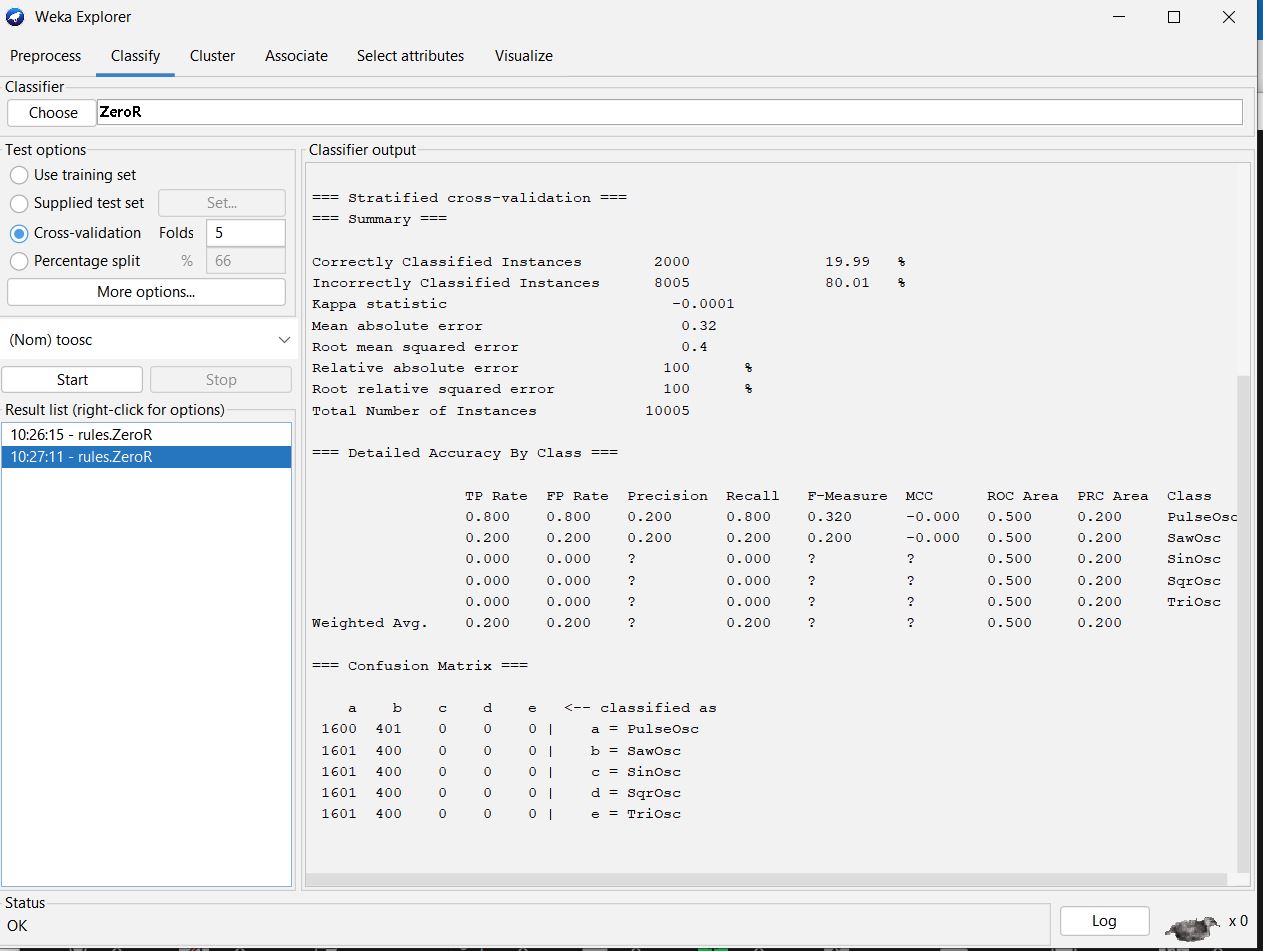
A ZeroR Confusion Matrix
for 5-fold Cross-validation
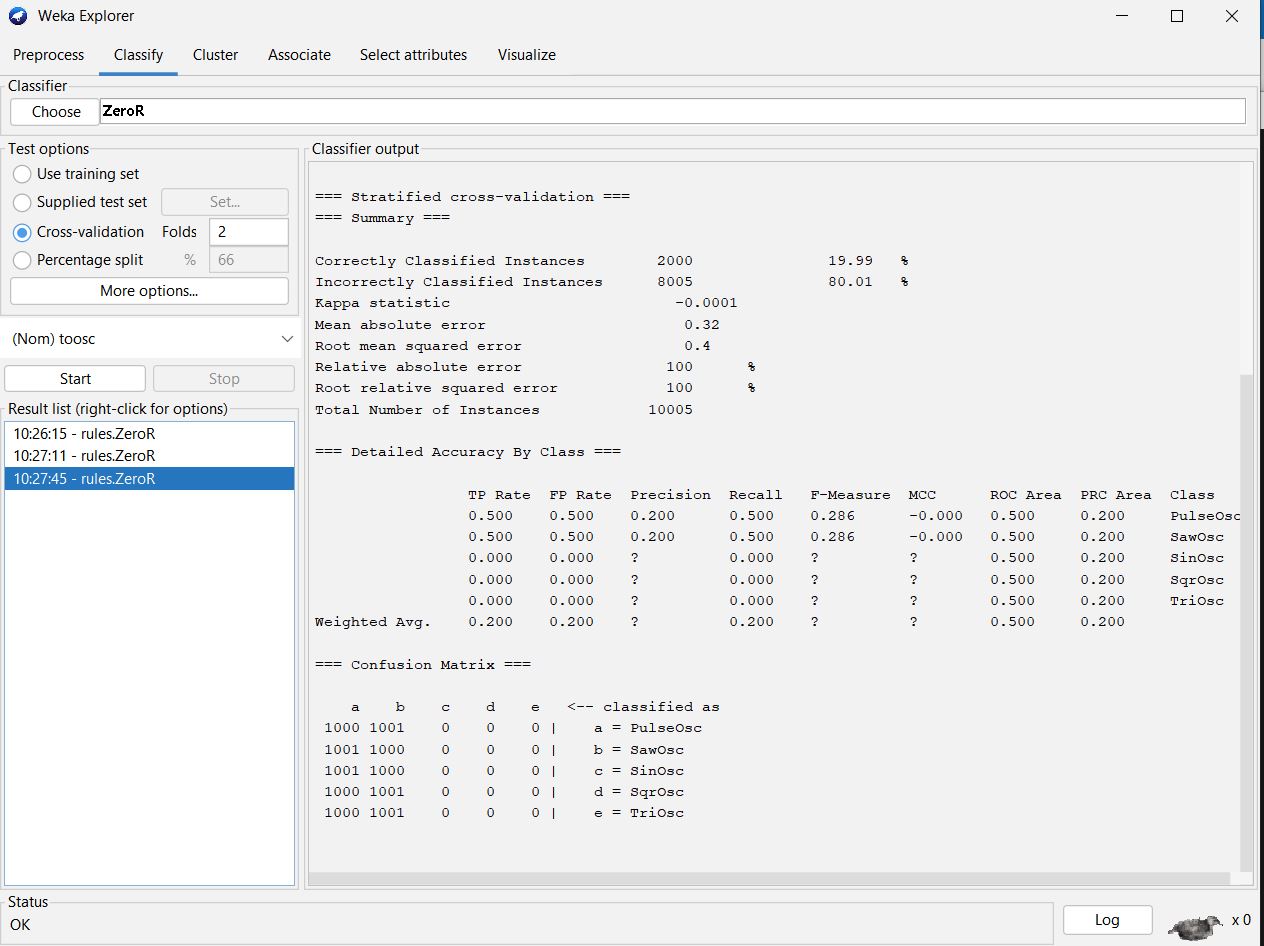
A ZeroR Confusion Matrix for 2-fold Cross-validation
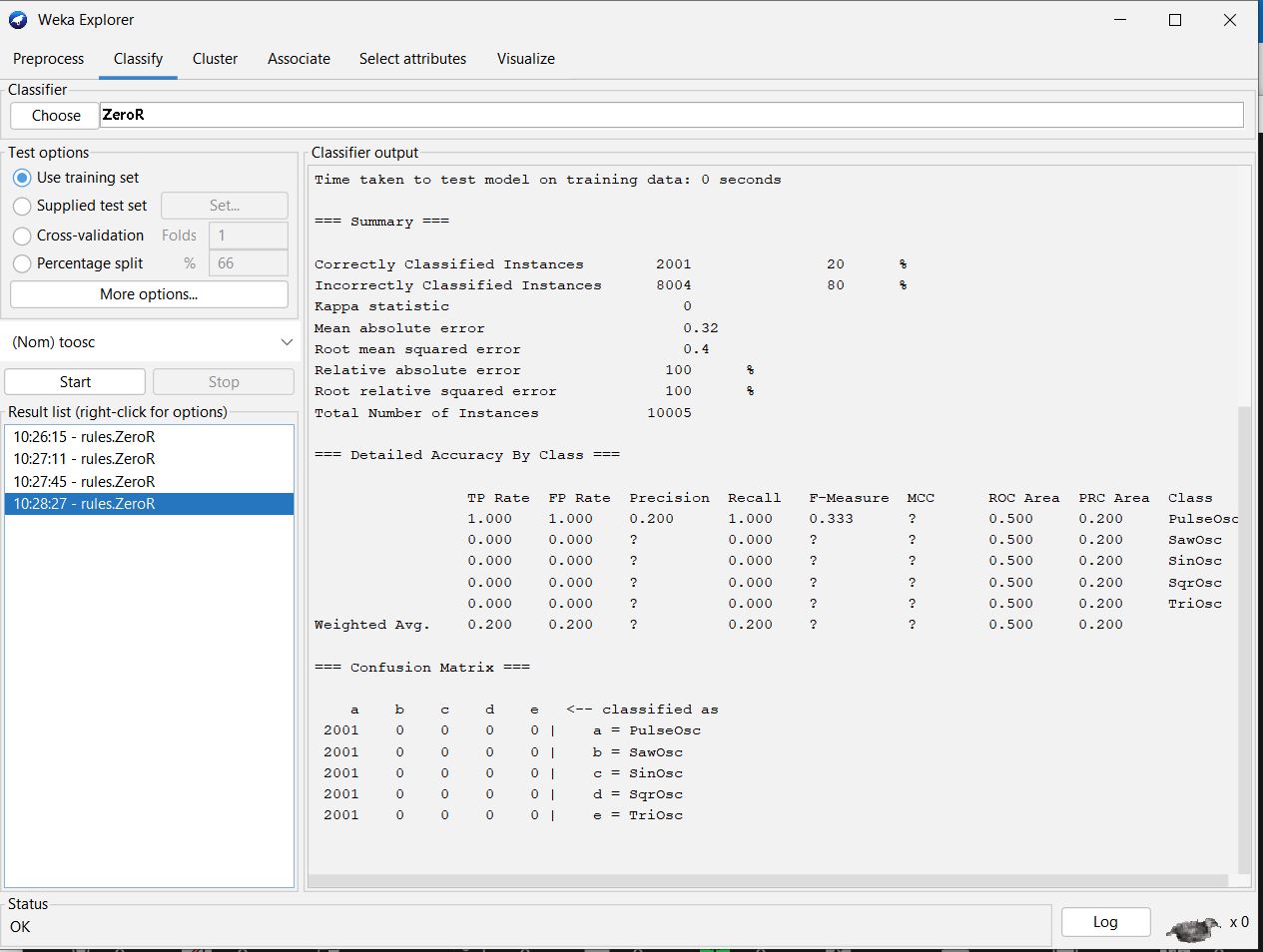
A ZeroR Confusion Matrix with training &
testing on the same 10,005 instances
The target-only (toosc) dataset used by ZeroR in the above
tests