1 Introduction
This paper is an experience report regarding upgrading a small, circular planetarium with a high-resolution raster projector to use an eight-channel circular sound system and semicustom software configured for synchronized creation and perception of music and projected computer graphics. This planetarium uses symmetric, circular seating, an arrangement that is increasingly uncommon in large planetariums, which use theatre-like, unidirectional seating of the audience. We discuss the benefits of circular seating for spatial audio and for spatial synchronization of sound with graphical objects.
The author’s perspective is that of a composer and performer of processed electro-acoustic music, spanning the gamut from signal-processed acoustic instruments, through analogue sound synthesis, to digital modelling of physical instruments. Emphasis is on creating synchronized musical and graphical instruments that include human performers in the stochastic, generative behaviours of the instruments. This paper reports recent efforts in extending this perspective to include spatial properties of a circular planetarium as a visual musical instrument.
2 Background
The earliest work that informs the present effort is the history and collection of images by Jordan Belson for the Vortex project in the Morrison Planetarium in San Francisco, in collaboration with electronic composer Henry Jacobs starting in 1957 [1]. “The planetarium staff even developed new equipment for the artists, including a device that created interference patterns, and engineers from Stanford University were brought in to build a special rotary-controlled device that swirled the music around the room from speaker to speaker in the manner of a vortex.” [1, p. 148]. The diverse compositional effectiveness of such hard-wired devices is impressive. Belson’s abstract, geometric visual designs are precursors to live visualizations derived from audio waveforms such as sndpeek [2], as well as our interactive, performance-based software illustrated in Figure 1.

Figure 1. Interactive visualization of electronic musical waveforms in the Kutztown Planetarium
A recent survey examines the hurdles in achieving standards for immersive spatial sound in planetariums [3]. That study examines a variety of topics including circular versus theatre seating arrangements, reflections from curved walls, 3D reflection from the dome, loudspeaker placement, loudspeaker correction to flatten frequency response, production issues, and a series of case studies. The present paper is a dedicated case study of spatial visual music enhancements at the Kutztown University Planetarium, taking the main issues of [3] into account.
The key concept guiding this new work is Blesser and Salter’s aural architect as described in their book Spaces Speak [4]. “An aural architect, acting as both an artist and a social engineer, is therefore someone who selects specific aural attributes of a space based on what is desirable in a particular cultural framework.” The aural architect is a hybrid creature who treads the spaces between acoustic engineer and composer/performer. While the author plays the role of composer more than aural architect, finding ways to make this space speak well is central to this project. Social requirements to make the space appear well at the possible expense of sounding its best, of utilizing the space primarily for non-musical applications – astronomy presentations and lectures in the present case – and of studying the aural architecture properties after the space has been designed, are all hurdles discussed by [4]. The emphasis on temporal reverberation properties as the most important acoustic properties to influence a listening space also comes out of this reference.
Reference [4] introduces the conceptual dichotomy of the protoinstrument and the metainstrument, where the former is a musical instrument in the traditional sense, and the latter is such a musical instrument performed in a space with temporal and spatial spreading [4, ch. 4]. The most ambitious prior visual music metainstrument in our planetarium was HexAtom, a software system that maps 11 stochastic attributes of simulated atoms in a visual universe to musical properties such as pitch, meter, and accent patterns [5]. Spatial sound treatment is very elementary, dedicating each of five 5.1 surround speakers to MIDI channels / protoinstruments. The most significant advance in this metainstrument is feedback between the visual and musical modalities; graphical object properties generate musical properties, and select musical properties use both regenerative and degenerative feedback in generating and destroying graphical objects. The present project is the first in our planetarium to tackle location of visuals and music as a primary compositional dimension.
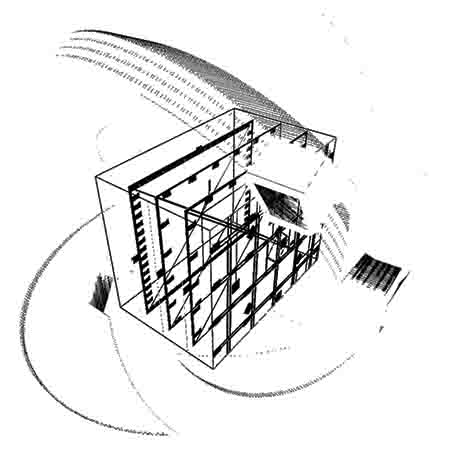
Figure 2. Interactive 3D animation directing sound in the VA Tech 148-speaker Cube, Cube Fest 2016.
The final background experience contributing to the present work was the author’s inclusion in the 2016, Second Annual Spatial Music Workshop and First Annual Cube Fest in the 148-speaker Cube, a cuboid sound design and performance space in the Virginia Tech Moss Arts Center [6]. The author prepared for the workshop by creating a 3D animated graphical model of the planetarium-size Cube in the Processing language [7] after downloading floor plans for the Cube that included speaker locations. The performance consisted of feeding six channels of analog audio from three feedback-driven no-input mixers into an audio router coded in SuperCollider [8]. The performer launched up to six satellite mini-cubes traveling in elliptical orbits around the main graphical Cube – Figure 2 shows three satellite mini-cubes – with each mini-cube routing sound for one audio channel to the closest of six Cube planar surfaces via networked messages from Processing to SuperCollider. The location of mixer channels in the immersive room followed the mobile locations of corresponding graphical mini-cubes.

Figure 3. Performing in the VA Tech Cube, 2016.
By day 3 of the five-day workshop the software was working for routing each audio channel to its own graphical and sonic surface of the Cube, but attempts to debug problems with subdividing the visual-music planar surfaces did not succeed in time for the Friday evening debut performance of Cube Fest. The author then changed the plan for the final movement of the piece by collapsing spatiality, simultaneously zooming in the graphical camera point-of-view to the point of smashing into the graphics of the central Cube and splattering the audio channels randomly among the speakers. The author also shifted the mixers into saturation, yielding a very non-spatial, spark plug-like timbre. This compositional tactic of synchronized destruction of visual and aural spatial perspective is actually another form of immersion. Becoming immersed in an environment often results in a loss of perspective. One of the other workshop participants began talking with the author about “following the piece” up to a point where it began to lose spatial coherence, but before the author answered that the spatially collapsed ending was a compositional tactic, another presentation began and the conversation ended. This tactic reappears with some nuance in the present work.
3 The Planetarium Speaks
This section summarizes
the key aural architectural characteristics of the Kutztown
University Planetarium. Figure 4 shows that the base of the
dome sits 2.4 meters (8 feet) above the carpeted floor. It is
10.7 meters (35 feet) in diameter, making the hemisphere 5.35
meters (17.5 feet) high. Each point on the dome is equidistant
from the fish-eye raster projector, which has a graphical
diameter of 1200 pixels, yielding 1,130,973 pixels on the dome
with a visual span of 0.15 degree per pixel. The dome consists
of acoustically transparent, perforated aluminium, painted to
minimize optical and aural reflections. The projected image is
actually a rectangle, and when not clipped to the central
circle, it spills about 0.6 meter onto the north, south, east,
and west walls. With the speed of sound at roughly 343 meters
per second, it takes about 31 milliseconds for sound to cross
the room at its full diameter.
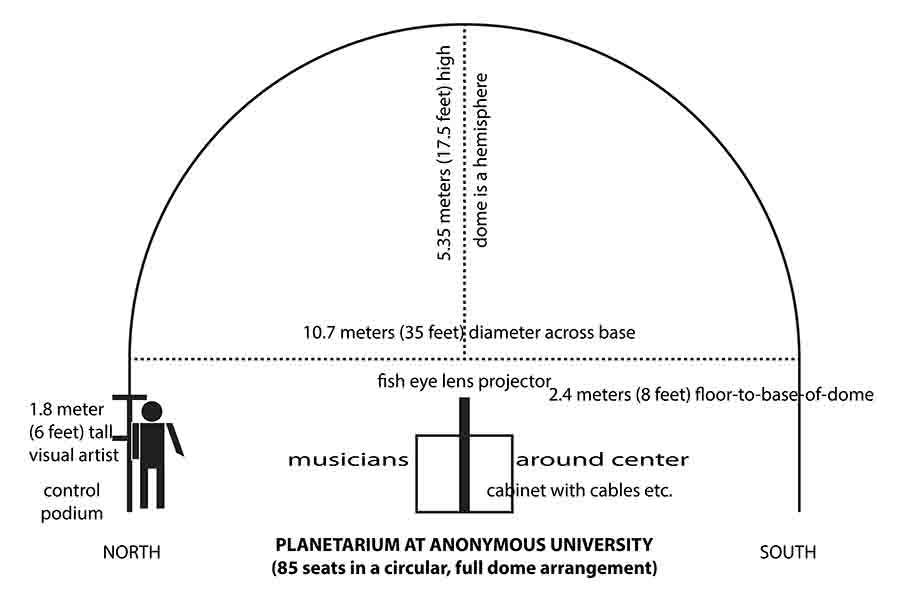
Figure 4. Cross-section of Kutztown Planetarium.
Figure 5 is a photo from a two-day workshop and concert series in June 2015. It gives an idea of the scale of the room. The projector podium in the centre has a diameter of about 1.2 meter (4 feet), growing to 1.8 meter (6 feet) when musicians place their equipment around it. The podium is about 1.5 meter high at the top of the projector, and acts as an early reflector of sound.
In May 2018 the author configured 6 QSC K12 – 75° 1000 W active 12" (300 mm) 2-way loudspeakers on stands at a height of 1.8 meter off the floor, behind the back rows of seats, spaced equally at 60° intervals. Most of the work reported in this section is based on this configuration, with two additional K12 speakers added with a reconfigured spacing of 45° near the end of August 2018. The speakers are not mounted in permanent positions behind the dome, as is conventional, in order to allow for experimental placement. Listeners must avoid seats directly in front of the speakers because sitting there saturates hearing with the output of one speaker.

Figure 5. Photo of the Planetarium from the west
Figure 6 gives the speaker layout from the perspective of lying on one’s back with one’s head to the north, looking up, which is a standard perspective for planetarium graphics work. This perspective is why east is to the left and west to the right; it is an ongoing source of temporary software bugs that incorrectly reflect coordinates around the Y axis that runs from north to south. North is at the top of raster display 2, south is at the bottom, east is on the display’s left, and west on its right. The darker region of Figure 6 shows the direct sound cone (without reflections) for 75° speaker S6. The vertical and horizontal bars are walkways, with hard wooden exit doors at the north and south. The aforementioned projector podium is in the centre, and the 85 seats are spaced in three concentric arcs around the podium, between the walkways. Note that the room is not a perfect circle. There are elliptical walkways behind the circular seats to the north and south. Most of the walls are perforated fibre board with relatively low sound reflection properties, but the two areas labelled “Hard wall” are painted plywood walls behind which are closets.
Figure 7 shows the 200 milliseconds it takes for a burst of noise (white noise or the author’s shout) to decay 24 dB to the level of a quiet room. All measurements were taken with no one else in the room. A Rode model NT5 unidirectional condenser microphone captured these recordings. The decay time was consistently around 200 milliseconds at various microphone locations and orientations in the room.
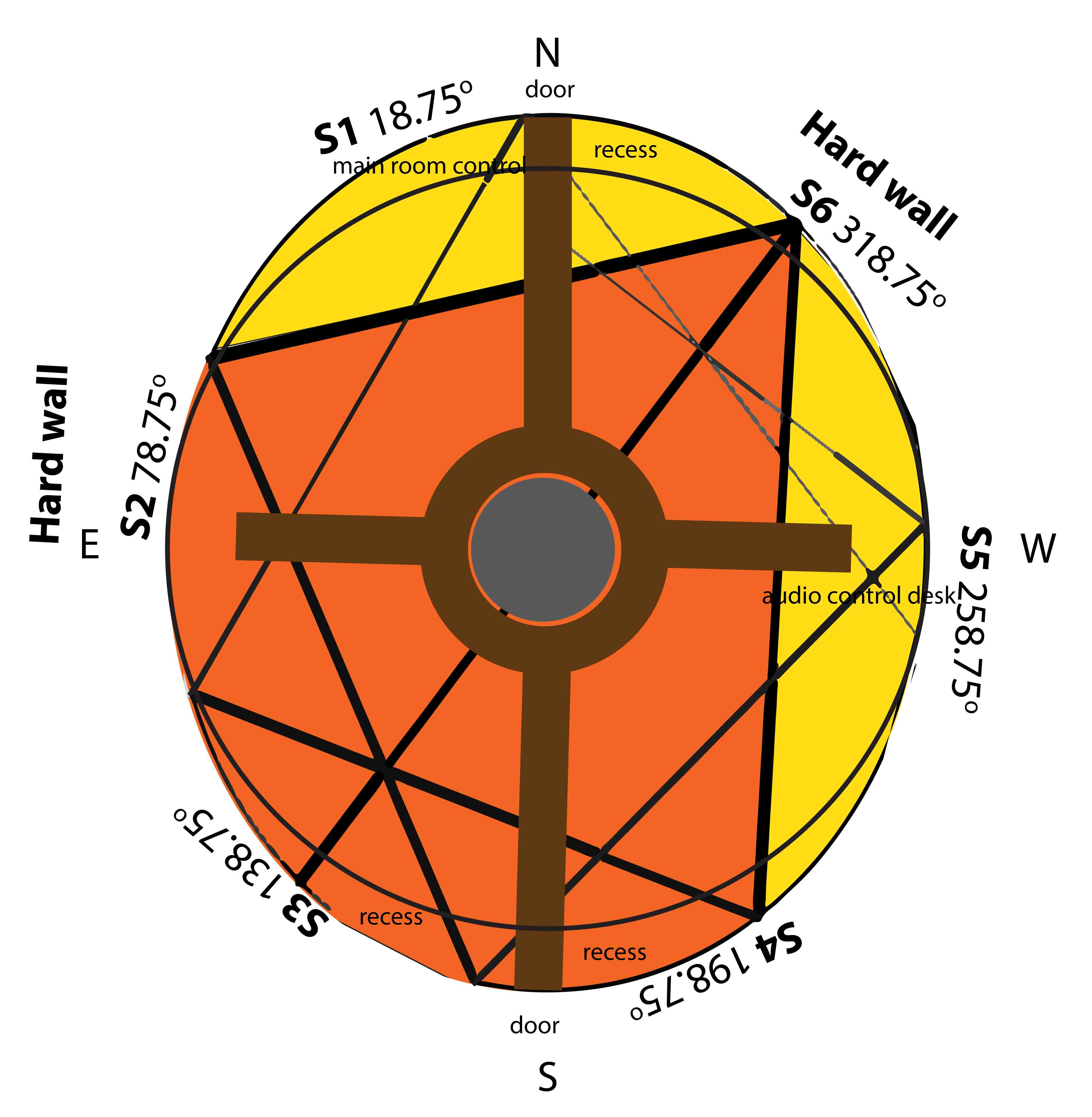
Figure 6. Speaker layout looking up from the floor
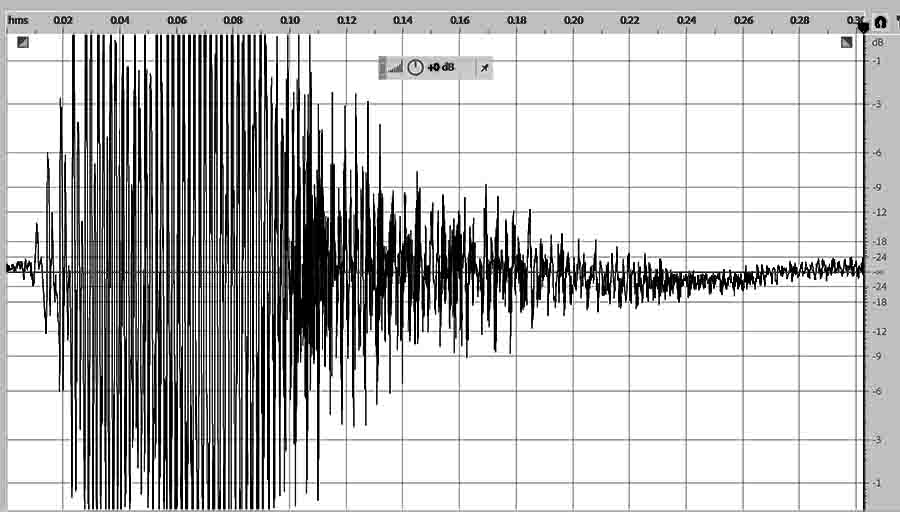
Figure 7. Noise decay from 0 dB to -24 dB in 200 ms.
Sound takes 31 milliseconds to reach the opposing circular wall for the direct 10.7 meter path across the centre of the room; it takes 24.6 milliseconds to traverse the outer 37.5° paths of a 75° speaker cone of Figure 6. With an average of (31 + 24.6) / 2 = 27.8 milliseconds, 200 milliseconds decay time represents the direct path + 6.2 reflections. The microphone recorded single-reflection drops of time-domain peaks ranging from 2 dB to 5 dB compared to the direct signals for the initial reflection of each speaker. An average 3.5 dB drop X 6.2 reflections yields a 21.7 dB drop in 200 milliseconds, a drop that accords with the decay graph of Figure 7.
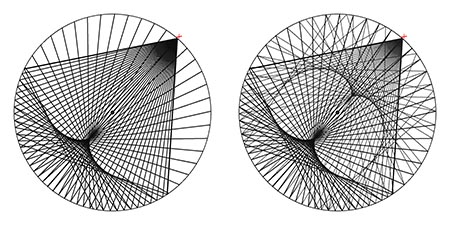
Figure 8. One and two reflections from a speaker
Spaces Speak warns against curved walls because they focus sound [4]. The left side of Figure 8 shows signal propagation across one reflection from one 75° speaker; the right side shows two reflections. However, circular seating mitigates most of the potential problem. When seated near the focal point of one reflection, the listener is facing the speaker across the central podium. The directional properties of hearing alone are enough for correct perception of the sound source, especially given the 2 dB to 5 dB drop on the wall behind the listener. Standing up and turning around is revealing, especially when the reflecting surface is a hard wall. With a limit of about 40 milliseconds for the sound to cross the room and reflect back one third of the diameter to the focal point, the timing of the reflected sound is below the 80 to 160 millisecond range for transition from early to late reverberation [4, p. 232]. The listener perceives the reflected sound in unison with the direct sound – there is no sense of delay – with the reflected sound spread out across the curved reflecting wall. Though the sound is focused on the listener, the reflected sound source is perceived as a wide, weakened field that reinforces the direct sound without masking its directionality. It is possible for a listener to find a head position where the lateral first-reflections compete with the speaker for perceived amplitude, but this position is between and well above seats, and movement of even a few inches out of the focal point reduces the perceptual competition. Walking to the reflecting wall completely eliminates the perceived reflection because the listener hears only a few reflected paths instead of the many at the focal point.
The focal point of the second reflection is not a problem because the speaker is close behind the listener’s head, and the twice-reflected sound is much diminished and scattered laterally.

Figure 9. Six reflections from a speaker
Figure 9 shows that after the average 6 reflections needed to complete the 200 milliseconds decay time for the room, the signal is much diminished with no directionality competing with the speaker location. There is no additional focal point after 2 reflections.
Spaces Speak summarizes the work of David Griesinger [9] that is relevant here. “In his view, the early part of the reverberation process fuses with the direct sound to form a unitary sonic event, which increases the aurally perceived size of the sound source…Morimoto and Iida described source broadening as ‘the width of the sound image fused temporally and spatially with the direct sound’ [10]…Like all sounds, this fused sonic event also produces temporary insensitivity to the reverberation energy immediately following. This is the principle of masking…Not only do the early reflections contribute to source broadening, but they also inhibit the experience of enveloping reverberation for about the next 100 milliseconds…there is only a small time window, between about 100 and 300 milliseconds, for creating the experience of listener envelopment: the continuous reverberation process is audible only during this time window. This window is squeezed between early sonic reflections of a given musical note and the next note after it.” [4, p. 233-234]
These extensive quotations are precise descriptions of the subjective experience of listening to music projected from these 6 speakers in the planetarium: A) Speaker directionality remains strong, regardless of the speaker or location of the listener, B) early reflections give the impression of an immersive sonic field that fuses with the direct sound at diminished amplitude, and C) late reflections are perceived as gentle resonance. There are no discrete echoes and no muddying of the sound by lengthy reverberations, regardless of the tempo and timbre of the music. There is also no perceptible reflection from the overhead dome. 200 milliseconds comprise the room’s cutoff, although sustaining sounds such as drones, and artificial reverberation, support the experience of enveloping reverberation.
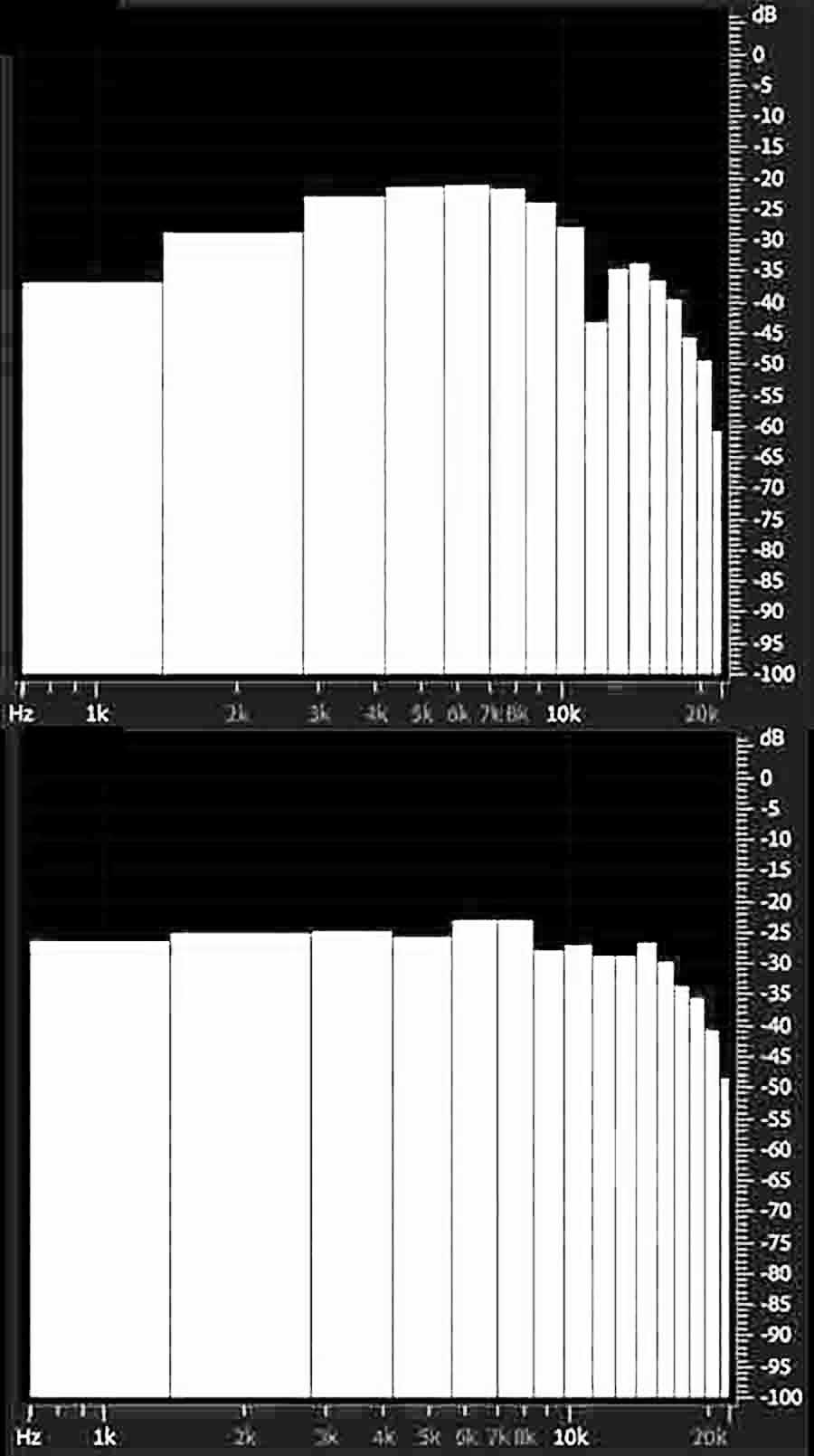
Figure 10. Frequency response to white noise pointing across the room to the space between S1 and S6 in Figure 6 (top), and S1 and S2 (bottom)
Figure 10 shows two representative frequency domain plots with a sampling rate of 22,100 Hz and a 32-sample Hamming window FFT, taken on white noise from across the room with the Rode NT5 mic, pointing between S1 and S6 in Figure 6 at the top of Figure 10, and S1 and S2 at the bottom. The attenuation in the 0-1.5 KHz range for the first comes from both the recess outside the circle at the northern door and the aural obstacles in the area labelled “main room control” at the north of Figure 6. There is a control podium, with S1 sitting back inside what is essentially a cavity, in order to minimize hazards for foot traffic to this area. The space between S1 and S2, in contrast, is at the end of the recess and the start of a hard wall, with S2 immediately behind the outer row of chairs. Figure 10 is representative of other frequency domain measurements in the room. The cluttered recesses attenuate the low end. The effect is not especially noticeable when listening to music. The solution is movement of the speakers away from recesses and the control console cavity, positioning them directly behind the outer arc of seats.
There is a plan to move the speakers up behind the base of the dome, currently occupied by five 5.1 surround speakers, subject to available time and the constraints on other uses of the room. This move will not fundamentally alter the horizontal reflection properties of Figures 8 and 9, but it will increase the amount of signal directed into the dome material and then reflected. Figure 11 shows the vertical reflection pattern from this speaker placement. The dome attenuates an audio signal by 9 dB as measured by the Rode NT5 mic. A single vertical reflection goes directly into the absorbing surfaces of listeners, chairs, and the carpeted floor. The vertical focal point of Figure 11 lies well above listeners’ heads, level with the base of the dome. Moving the speakers up from 1.8 meter to 2.4 meters in Figure 4 elevates the focal points of Figure 8 in relation to listeners. The dome material is almost transparent to speakers placed behind it, and there is plenty of headroom in the amplified speaker levels. Finally, this move will reduce the audio signal shadows of the central podium. Based on this analysis and experience with the 5.1 speakers currently mounted behind the dome, this move will be beneficial for listeners.
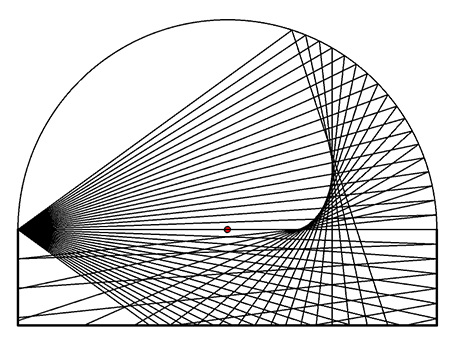
Figure 11. One vertical reflection from the dome
The author is a strong proponent of the subjective experience of listening. The author is also an experienced composer, performer, instructor, and conductor in the art of playing the feedback-driven no-input mixer. No-input mixing routes mixer output buses to inputs, through various mixer filters such as equalizers, compressors, and effects, and taps the generated feedback signal as the performance output [11]. Experience has shown that portable, typically less expensive mixers that colour the timbre and tonality of the feedback sound make better instruments than extremely dry mixers with flat frequency response curves. The latter mixers are the best for mixing because they do not taint mixed signals, but they are inadequate for no-input mixing because they all have the same sound and lack of distinctive character. Part of the current investigation entailed placing an AKG Perception 400 condenser microphone in its omnidirectional setting at the centre of the planetarium, routing its signal to six channels in Ableton Live, with each channel containing an identical compressor to avoid over-driving the speakers and damaging listener hearing, and then routing each of the six channels out to a respective speaker from Figure 6. This experiment uses feedback from the room itself as the no-input mixer. The author brought the individual input channels up very slowly and carefully. Increasing gain on one channel affects all channels because they share a common input mic. The result was a very dry, clean feedback sound with no tonal coloration. It is uninteresting from the no-input musical perspective because all tone and timbre must be added by electronics or software models in the feedback paths; the room has no no-input character of its own. This clean, dry characteristic is ideal for a room that must support many kinds of music. The experiment shows, at least from a perceptual perspective, that the room’s frequency-response characteristics are very good.
4 Visual Musical Configurations
This section summarizes a number of multi-musician configurations available to composition in the circular seating-graphics-speaker planetarium of Figure 6. The approach is channel based, relying on a priori knowledge about the location of the loudspeakers and their relationships to the listeners [12, p. 3]. This is not a more technically advanced sound field or wave field system. The potential of channel-based circular systems has not been exhausted; the current effort extends the compositional structure of channel-based, circular surround sound.
The first class of configurations has structure similar to live musicians playing among listeners, physically, in an intimate chamber such as a small planetarium. In fact, that is the most common performance scenario in this space. For starters, 8 speakers can support 8 simultaneous monophonic musicians (human or virtual), 4 simultaneous stereophonic musicians using disjoint speakers, or 8 simultaneous stereophonic musicians using overlapping speakers (one musician’s L is another musician’s R). It is also possible for a stereo musician to span 3 adjacent speakers, with (L+R) / 2 going to the centre speaker. Spatial topology is discrete, i.e., there is no continuous signal blending across speakers.
An immediate problem for a listener in the room is that speaker proximity dominates the listening experience. A listener mostly hears the closest speaker / musician. A solution is to rotate the speaker assignment of channels periodically, so that listeners experience virtual moves around the room. No single instrument voice / speaker dominates a listener’s experience of a piece.
Even more interesting is to permute the speaker assignment of channels as a first-class compositional structure. Four stereo musicians span 4! = 24 configurations if each rotation is considered a separate configuration, or 3! = 6 if rotations are considered equivalent, although, from a given listener’s perspective, they are not equivalent. [[1, 2, 3, 4], [1, 2, 4, 3], [1, 3, 2, 4], [1, 3, 4, 2], [1, 4, 2, 3], [1, 4, 3, 2]] X 4 rotations gives the possible configurations for 4 disjoint stereo musicians. For 8 disjoint monophonic musicians or 8 overlapping stereo musicians there are 8! = 40,320 permutations, or 7! = 5,040 permutations for rotation equivalence. Despite the established nature of discrete channel-based speaker assignment in this age of high density speaker arrays and wave field spatialization, the compositional practice of channel assignment has room for invention. In some aesthetic sense, sound field and wave field spatialization are to channel-based spatialization as microtonal composition is to composition using equally tempered or just intonation scales. Spatial intervals are discrete, so there are fewer of them, but they offer useful constraints against which to compose. From a listener’s point of view, hearing phrase-structured changes in the juxtaposition of instrument voices, in conjunction with other temporal musical phrase structures, adds a massive dimension to the musical experience.
Figure 12 opens the discussion of the main visual music compositional approach conducted in the planetarium during summer 2018. It consists of four complete screenshots of a single graphical entity, an ellipse, used as a paintbrush on the dome. A paintbrush can be a simple geometric shape, a raster image from a photograph, a vector file created with a drawing program, or even a recursive snapshot of the program’s display from an earlier frame. This dome painting program captures the history of a paintbrush application in multiple ways [13]. The top-left ellipse shows a single application of graphical paint with no history. The top-right shows the paintbrush leaving a trail of 9 previous applications; the program erases the earliest tail-image as it adds a new one. The bottom-left shows rotation and scaling of the canvas itself, after it has been painted; post-application manipulation of the canvas tends to blur paintbrush applications because of inexact alignment of pixels in a visual analog to the erosion of spatial alignment in the multiple-reflection paths of Figure 9. The bottom-right shows reflections of the current paintbrush around the vertical and horizontal axes, combined with a 90° rotation of the canvas in each frame. A 90° rotation without scaling gives exact pixel alignment, so there is no blurring. Figure 13 gives a sample of the visual complexity of the program, which is much more complex during animated performance. The top-left shows application of an elliptical and a rectangular paintbrush with a history of canvas manipulation, and the top-right shows the canvas a minute later, with the addition of a recursive paintbrush that duplicates the previous frame’s canvas every 60th of a second. The bottom row shows another pair of temporally sequential screen shots.

Figure 12: Four applications of the same paintbrush

Figure 13. Two demo runs of dome painting
The location of a given channel of audio follows its paintbrush as it moves around the dome. In the present implementation the paint program sends the current location of each paintbrush, once per graphical frame, to the 2D Surround Panner in Ableton Live 10 [14] via MIDI controller messages. Plans to move to Open Sound Control (OSC) [15] for network distribution of graphics and sound manipulation, and migration from Live to SuperCollider in support of channel permutations discussed above, will begin in early 2019.
When the dome display becomes very busy, tracking the current location of the paintbrushes that are routing instrument channel locations becomes difficult. After extensive experimentation with listener/viewers, a few rules of thumb emerge: A) Use brush histories that alter appearance, such as rotation + scaling of the canvas that blur previous pixels; B) avoid manipulations such as reflection and pixel-preserving rotations that create graphical object aliases, obscuring the identity of the sound-directing brush; C) do not move brushes so quickly that they are hard to track and listen to; D) do not put an excessive number of brushes / instrument channels on the canvas / speakers at one time. Maintaining these guidelines takes compositional planning and performance practice.
It is not strictly necessary to avoid visual-aural ambiguity. In addition to the severe collapse of spatiality described for the Cube performance in Section 2, it is possible to immerse listener / viewers in complex animations like Figure 13 while simultaneously immersing them in complex, but not chaotic manipulations of sound location. Indeed, many established visual music composers have eschewed tight visual-aural synchronization in favour of loose correlations and visual-aural dialogues [16]. When skilfully executed, immersion in animations / spatial music that is a little too hard to track causes listeners to let go and just be immersed in visuals and music, without obsessively tracking locations.
As a simple example, an early experiment split the room into stereo, left being assigned to the three speakers on the east side of the room in Figure 6, and right being assigned to the three speakers on the west. Running a stereo signal through the Ableton Live stereo panner, with panning modulated by a 1 Hz sine wave, gave the room the distinct feeling of wiggling back and forth in size. The room felt like its space was dancing. Synchronizing the timing of spatial sound motion not only with graphical objects, but also with other musical properties such as meter, tempo, syncopation, reverberation, and other compositional and performance effects, gives listeners more complete immersive experiences.
5 Conclusions and Future Work
The history of spatial, visual music in planetariums, combined with previous experience, and a dedicated study of perceptible room acoustics, lead to an increased awareness of opportunities for creative spatial composition and performance. Performance work in the room that started in 2011 has always given the impression of good acoustics that this detailed study reinforces and extends.
Aural reflections from circular walls do not create major problems when combined with circular seating. Unidirectional theatre seating would be more problematic, because listeners would be facing reflections for some speakers throughout the performance. There is no sweet spot in a circular seating planetarium. The problem of a listener being dominated by the closest speaker is largely ameliorated by rotating or permuting channel-to-speaker routing as part of the performance.
Classic graphics such as waveform visualizations can be spatial by giving each speaker its own graphic waveform paintbrush above the speaker. When a limited number of unambiguous graphical objects guide speaker routing at a reasonable pace, listener / viewers can maintain sound / graphic correlations without trouble. When the identities of graphical objects become ambiguous or aliased, or when they become too fast or many, listener / viewer disassociation of sound location from graphical location can act as another compositional tool.
Future work includes composing with dynamically permuted channel-to-speaker assignments. Beyond that, the opportunity to experiment with speakers above the dome will create opportunities for technical and compositional 3D sonic work in the planetarium.
6 Acknowledgements
The Kutztown University of PA Research Committee provided funding for the equipment and software used in this study.
The author would like to thank Eric Lyon and Tanner Upthegrove of Virginia Tech, and Willie Caldwell of Miami University, for inviting, hosting, and teaching me at the 2016 Spatial Music Workshop and First Annual Cube Fest. That magical week was the main catalyst for this current project.
Thanks also go to Phill Reed, the ever-supportive Director of the Kutztown University Planetarium.
References
[1] Brougher, Strick, Wiseman, and Zilczer, Visual Music, Synaesthesia in Art and Music Since 1900, Thames & Hudson (2005).
[2] Wang, Cook, Misra, and Tzanetakis (MARSYAS), sndpeek : real-time audio visualization (2003-2015), https://www.gewang.com/software/sndpeek/, link verified September 2018.
[3] Gaston, et. al., “Methods for Sharing Audio Among Planetariums,” 2008 Fulldome Summit, Chicago, Illinois, July 3, 2008, http://whiteoakinstitute.org/IPS2008.pdf.
[4] B. Blesser and L. Salter, Spaces Speak, Are You Listening?, MIT Press (2007).
[5] D. Parson and P. Reed, "The Planetarium as a Musical Instrument," Proceedings of the 2012 New Interfaces for Musical Expression Conference, Ann Arbor, MI, May 20 - 23, 2012.
[6] Virginia Tech Moss Arts Center, Spatial music festival pushes the boundaries of sonic innovation in the Cube (July 25, 2016), https://vtnews.vt.edu/articles/2016/07/icat-cubefest.html.
[7] Processing home page, https://processing.org/, link verified September 2018.
[8] SuperCollider home page, https://supercollider.github.io/, link verified September 2018.
[9] Griesinger, D., “Objective measures of spaciousness and envelopment,” Proceedings of the Nineteenth International Conference of the Audio Engineering Society: Surround Sound: Techniques, Technology, and Perception (1999).
[10] Morimoto, M. and Iida, K., “A new physical measure for psychological evaluation of sound fields: Front/back energy ratio as a measure of envelopment.” Abstract. Journal of the Acoustical Society of America, 93:2283 (1993).
[11] Lumens, M., Feedback (No-input Mixing), Electro-Music.com, http://electro-music.com/wiki/pmwiki.php?n=Articles.FeedbackOrNoInputMixing (2013), link verified September 2018.
[12] Roginska, A. and Geluso, P. (editors), Immersive Sound, The Art and Science of Binaural and Multi-Channel Audio, Focal Press (2018).
[13] D. Parson, “Creative Graphical Coding via Pipelined Pixel Manipulation,” Proceedings of the 33rd Annual Spring Conference of the Pennsylvania Computer and Information Science Educators (PACISE) Shippensburg University of PA, Shippensburg, PA, April 6-7, 2018.
[14] Ableton Live, Max for Live Surround Panner, https://www.ableton.com/en/packs/surround-panner/, link verified September 2018.
[15] Open Sound Control, an Enabling Encoding for Media Applications, http://opensoundcontrol.org/, link verified September 2018.
[16] Abbado, A., Visual Music Masters: Abstract Explorations: History and Contemporary Research, Skira (2017).