CSC 523 - Scripting
for Data Science, Fall 2022, Assignment 4 (official).
Assignment 4 due by 11:59 PM on Tuesday November 22 via "make
turnitin". You must test on mcgonagall.
After 11/7 handout class:
As I mentioned in class, in
CSC523Fall2022TimeMIDI_generator.py, lines 198 and 207 in the
original handout pseudo-code:
198 # APPEND the notenum into list
TmovementChannelToTonic[key][0].
207 # APPEND the notenum into list
TmovementChannelToTonic[key][0].
SHOULD SAY:
198 # APPEND the (notenum%12) into
list TmovementChannelToTonic[key][0].
207 # APPEND the (notenum%12) into
list TmovementChannelToTonic[key][0].
That modulo 12 operator has to be in there to discard the octave
(how far up the piano keyboard), which is irrelevant to our
analysis.
Also if you cannot find CSC523Fall2022TimeMIDIOut.sorted.txt.ref,
it is here:
~parson/DataMine/CSC523Fall2022TimeMIDI/CSC523Fall2022TimeMIDIOut.sorted.txt.ref
I fixed both problems & re-zipped the handout .zip file, but
if you got an earlier version, you'll need this info.
1. To get the assignment on
mcgonagall (ssh mcgonagall or ssh kupapcsit01
from acad):
mkdir ~/DataMine #
(This is in your home directory; it may exists if you took one of
my data science courses.)
cd ~/DataMine
cp
~parson/DataMine/CSC523Fall2022TimeMIDI.problem.zip
CSC523Fall2022TimeMIDI.problem.zip
unzip CSC523Fall2022TimeMIDI.problem.zip
cd ./CSC523Fall2022TimeMIDI
make clean test
# This fails on handout code due to
mising code.
# ADDED 11/5 if you
get an error ModuleNotFoundError: No module named
'xgboost', just comment out the import of xgboost.
# Thanks to Bob Elward for
the catch. I updated the handout code late 11/4.
These are the attributes we will use in this analysis in
fall2022concert_train.arff.gz and fall2022concert_test.arff.gz.
We discussed time-series data analysis and this dataset on
October 31.
@attribute movement numeric
# A movement of a musical piece, conceptually a song, numbered 0
through 3.
@attribute channel numeric
# A MIDI channel, conceptually a musician
playing an instrument, numbered 0 through 3.
@attribute command {noteon, noteoff} # Whether
the musician has just played or stopped playing a note.
# handout code filters out noteoff
because it adds no information to scale analysis,
# then removes attributes command and
velocity. It must wait to remove attribute
# command until it has removed noteoff
instances so it can find them.
@attribute notenum numeric
# The note 0 through 127 being played. Think
of a piano keyboard.
@attribute velocity numeric
# How hard the note is played,
irrelevant for scale analysis.
@attribute tick numeric
# The
time with the (movement, channel) sequence, needed for note
lagging
@attribute ttonic numeric
# The so-called "do
note" or tonic or root, which is the key pitch of the scale.
# Initially ttonic
is tagged data by the score generator.
# Handout code
derives an empircal ttonic by taking the statistical mode of the
notes
# played in a given
(movement, channel).
@attribute tmode
{Ionian,Mixolydian,Lydian,Aeolian,Dorian,Phrygian,Locrian,Chromatic}
# scale being played
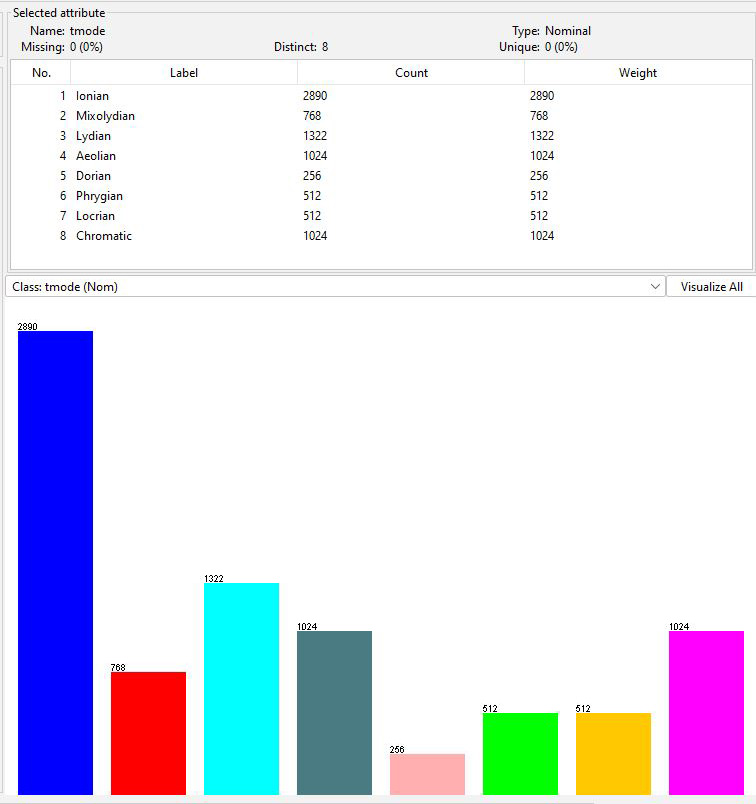
Figure 1: Distribution of tmode in the training dataset
We will classify tmode from other attributes. The test dataset
has an identical but independent distribution to the training
data. My
genmidi.py Jython script generated training and testing
data using different pseudo-random number seeds with
distributions seen in that link. You do not need to understand
the music theory in genmidi.py to do the assignment.
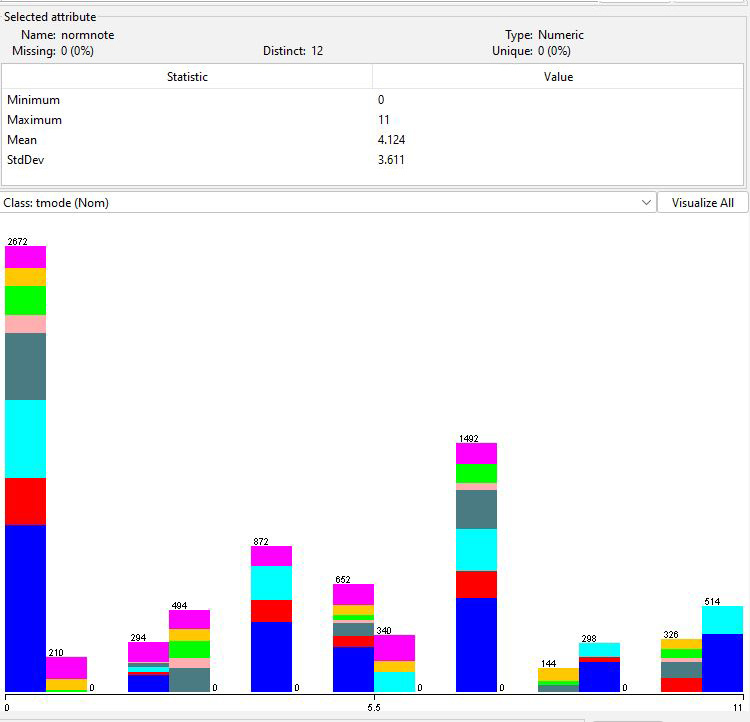
Figure 2: Distribution of normalized notes in the original
data colored by correlation to tmode
In Figure 2 a normalized note is the notes distance from the
tagged ttonic, which is the generator's intended "do" note in
the tmode. My preparation script extracts an actual "do" note as
the statistical mode (most frequently occurring value) of the
normalized notes. Here is some diagnostic output from that
script.
Computed and tagged tonic by (movement,channel):
('test', 0, 0) -> [7, 7]
('test', 0, 1) -> [7, 7]
('test', 0, 2) -> [7, 7]
('test', 0, 3) -> [7, 7]
('test', 1, 0) -> [9, 9]
('test', 1, 1) -> [9, 9]
('test', 1, 2) -> [9, 9]
('test', 1, 3) -> [9, 9]
('test', 2, 0) -> [7, 7]
('test', 2, 1) -> [7, 7]
('test', 2, 2) -> [7, 7]
('test', 2, 3) -> [10, 7]
('test', 3, 0) -> [7, 7]
('test', 3, 1) -> [7, 7]
('test', 3, 2) -> [7, 7]
('test', 3, 3) -> [7, 7]
('train', 0, 0) -> [7, 7]
('train', 0, 1) -> [7, 7]
('train', 0, 2) -> [7, 7]
('train', 0, 3) -> [7, 7]
('train', 1, 0) -> [9, 9]
('train', 1, 1) -> [9, 9]
('train', 1, 2) -> [9, 9]
('train', 1, 3) -> [9, 9]
('train', 2, 0) -> [7, 7]
('train', 2, 1) -> [7, 7]
('train', 2, 2) -> [7, 7]
('train', 2, 3) -> [1, 7]
('train', 3, 0) -> [7, 7]
('train', 3, 1) -> [7, 7]
('train', 3, 2) -> [7, 7]
('train', 3, 3) -> [7, 7]
All extracted tonics are the same as the tagged tonics except
for these two:
('test',
2, 3) -> [10, 7]
('train',
2, 3) -> [1, 7]
This mismatch occurs because channel 3 uses a chromatic
scale (mode) with uniform note distribution in movement
2, scattering notes with no pronounced tonic center.
Channel 2 also uses a chromatic scale with
uniform note distribution in movement 2.
Channels 0 and 1 use more constrained modes
but with uniform distribution in movement 2.
Movements 0, 1, and 3 use Gaussian
generation of notes in the tmode, generating
more predictive notes for each target mode.
Handout
code also derives these attributes:
@attribute lagNote_0 numeric
@attribute lagNote_1 numeric
@attribute lagNote_2 numeric
@attribute lagNote_3 numeric
@attribute lagNote_4 numeric
@attribute lagNote_5 numeric
@attribute lagNote_6 numeric
@attribute lagNote_7 numeric
@attribute lagNote_8 numeric
@attribute lagNote_9 numeric
@attribute lagNote_10 numeric
@attribute lagNote_11 numeric
These are histogram sums of intervals in one scale with the
ttonic at lagNote_0 being the extracted ttonic and the others
being steps on the piano above that, up to but not including the
next octave. The so-called FULL datasets include all of the
above attributes, while the MIN datasets include only the latter
12-interval counts.
2. Edit CSC523Fall2022TimeMIDI_generator.py
and search for upper-case STUDENT comments. The
requirements with % point values are there. There is also a
file README.txt in which you must answer questions.
The code is worth 30% of the assignment and README.txt the
remaining 70%. You can work on the README.txt before
completing the code if you want since it uses the Reference
files of expected output.
MAKE SURE to search for all upper-case STUDENT comments.
3. We will go over this handout code in class
on November 7. When you are ready to test your code, type make
clean test in the code directory. A successful
test run looks like this:
$ make clean test
/bin/rm -f *.o *.class .jar core *.exe *.obj *.pyc
__pycache__/*.pyc
/bin/rm -f junk* *.pyc CSC523Fall2022TimeMIDITrace.txt
CSC523Fall2022TimeMIDIOut.txt
/bin/rm -f *.tmp *.o *.dif *.out *.csv __pycache__/*
/bin/rm -f ./MIDIdata/* DEBUG*arff*
/bin/rm -f CSC523Fall2022TimeMIDITrace.txt
CSC523Fall2022TimeMIDIOut.txt
CSC523Fall2022TimeMIDIOut.sorted.txt.ref
/usr/local/bin/python3.7 CSC523Fall2022TimeMIDI_main.py
CSC523Fall2022TimeMIDITrace.txt CSC523Fall2022TimeMIDI_generator
fall2022concert_train.arff.gz fall2022concert_test.a
rff.gz > CSC523Fall2022TimeMIDIOut.txt
diff --ignore-trailing-space --strip-trailing-cr
CSC523Fall2022TimeMIDIOut.txt CSC523Fall2022TimeMIDIOut.txt.ref
> CSC523Fall2022TimeMIDIOut.txt.dif
sed -e 's/^TIME[^D]*DATA/DATA/' <
CSC523Fall2022TimeMIDITrace.txt >
CSC523Fall2022TimeMIDITrace.tmp
diff --ignore-trailing-space --strip-trailing-cr
CSC523Fall2022TimeMIDITrace.tmp
CSC523Fall2022TimeMIDITrace.txt.ref >
CSC523Fall2022TimeMIDITrace.txt.dif
# grep DATA CSC523Fall2022TimeMIDIOut.txt.ref | sort -rn -t' '
-k13 --stable | sed -e 's/^DATA/\nDATA/' | grep REGRESSOR >
CSC523Fall2022TimeMIDIOut.sorted.txt.ref
# echo "" >> CSC523Fall2022TimeMIDIOut.sorted.txt.ref
grep DATA CSC523Fall2022TimeMIDIOut.txt.ref | sort -rn -t' ' -k17
--stable | sed -e 's/^DATA/\nDATA/' | grep CLASSIFIER >>
CSC523Fall2022TimeMIDIOut.sorted.txt.ref
4. Make sure to answer all questions in README.txt.
You can do this before your coding is working.
5. After make clean test works without
errors (terminates without an error message) and README.txt
is answered, type make turnitin and hit Enter at the
prompt to get your work to me before the deadline.
If you make subsequent changes and make clean test still
passes, you can run make turnitin again and over-write
your previous submission. Note that this is not the "turnin"
script you may have used in other courses.
There is a 10% per day penalty for late assignments in my courses
and I cannot grant any points after I go over a solution.