then you need to wrap a call to
round(DIVISION, 6) around your DIVISION IN STUDENT 4.
This is the dvision as it appears in the comment:
# (cellvalue-minvalueforthatcolumn)
# /
(maxvalueforthatcolumn-minvalueforthatcolumn),
Added 9/12:
The
comments for my findInName2Col(...) and your
findOutName2Col() incorrectly state:
map (Python
dict) that maps the column number as an int to the name of
the attribute stripped of leading & trailing blanks.
IT SHOULD
SAY:
map (Python
dict) that maps the name of the attribute stripped of
leading & trailing blanks to the column number as an
int.
My
findInName2Col(...) is implemeted correctly. Only the
comments are backwards.
Also, the
error messages disappear in a useful order if you complete
STUDENT requirements 5 & 6 before 3 & 4, since
function normalizePerMinMaxMutateInPlace(normdatarows,
noNormalizeColSet) that contains 3 & 4 runs after 5
& 6.
1. To get the assignment on acad
(kuvapcsitrd01.kutztown.edu) or mcgonagall (ssh kupapcsit01
from acad): mkdir ~/DataMine #
(This is in your home directory; it may exists if you took one of
my data science courses.) cd ~/DataMine cp
~parson/DataMine/CSC458assn1SLOPESfall2022.problem.zip
CSC458assn1SLOPESfall2022.problem.zip unzip CSC458assn1SLOPESfall2022.problem.zip cd ./CSC458assn1SLOPESfall2022 make clean test
# This fails on handout code as follows:
2. Edit findPeaksValleys.py and search
for upper-case STUDENT comments. The requirements
with % point values are there.
See the
course page on Notepad++ if you are new to our Linux
systems, or you can log in and use the vim or emacs editor.
Scroll down to Basic
UNIX Information on this page.
The Purpose of this code is to open the CSV
file in the command line above (year_aggregate_HMS_1976_2021_kupapcsit01.csv),
load 46 years of annual raptor counts and weather statistics from
Hawk
Mountain Sanctuary's North Lookout, then iterate through the
data attributes (columns) following "-year" on the above command
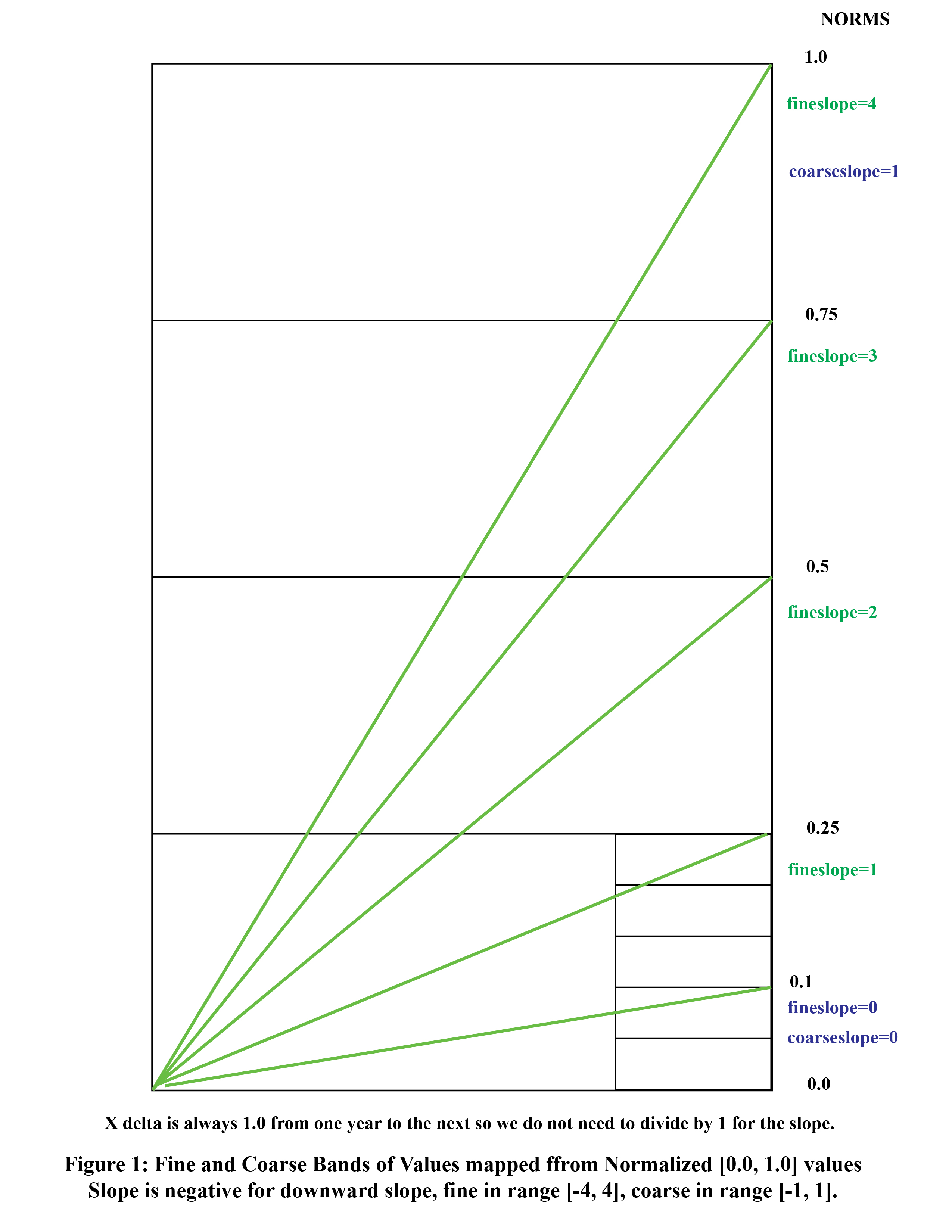
line, and find their peaks and valleys in two ranges, fine (range
[-4,4]) and course (range [-1, 1]) according to the following
illustration.
Script findPeaksValleys.pynormalizes each column
that does not start with a "-" on the command line (e.g., "-year")
into the range [0.0, 1.0], where 0.0 is the scaled minimum numeric
value for that column, 1.0 is the scaled maximum value for that
column, and values in between are scaled according to the formula:
(value-min) / (max-min)
This normalization maps attributes named on the command
line into the same [0.0, 1.0] scale for viewing together. Script findPeaksValleys.py
goes on to look at the slope of each normalized attribute change
for attributes listed in the command line, recording the positive
or negative slope as a discrete integer _FineNum attribute [-4, 4]
and a _CoarseNum attribute [-1,1], where Figure 1 shows the
boundaries for the discrete slope values. A downward slope is
negative.
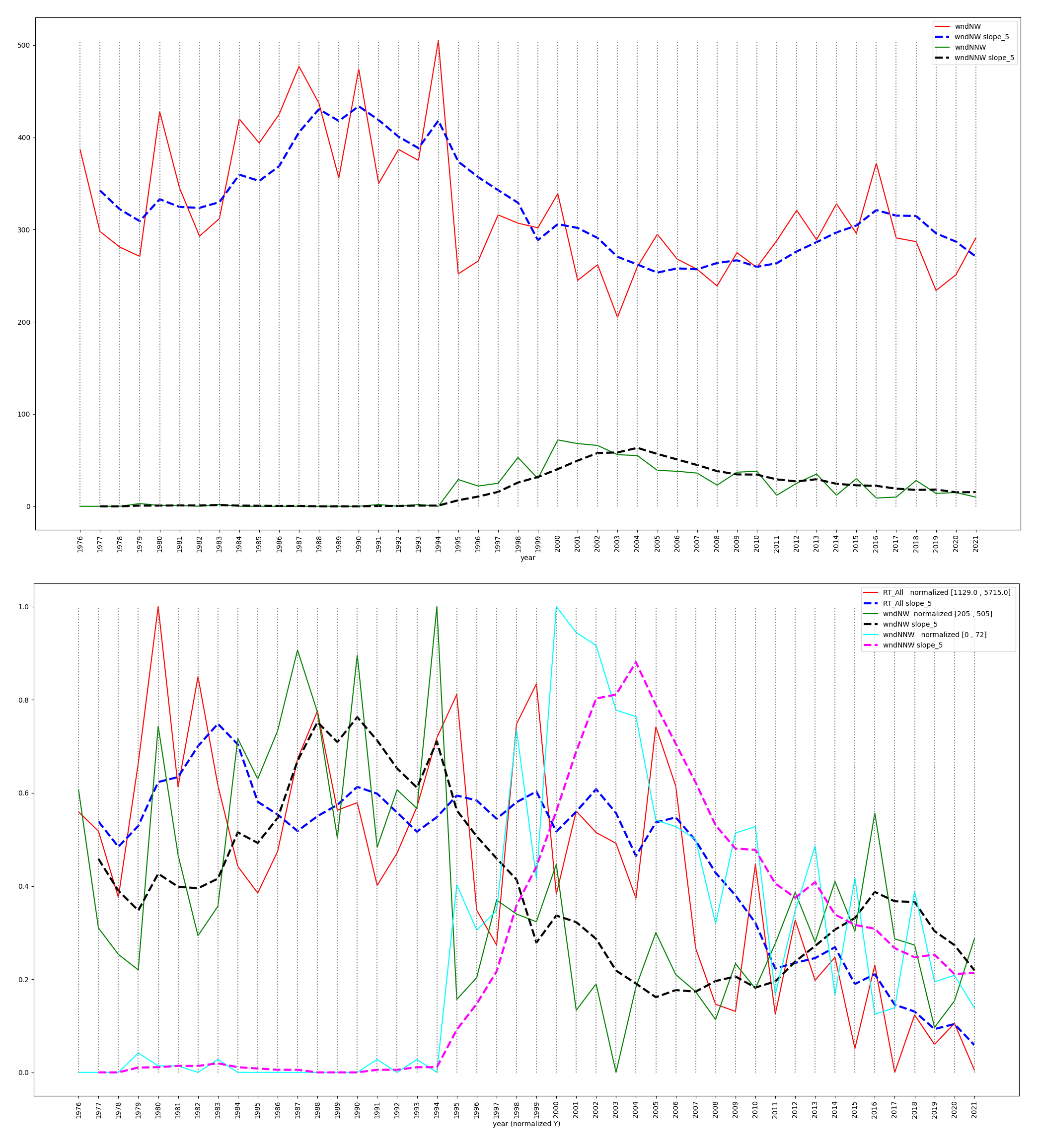
Figure 2 is Figure 23 in the 2022 Hawk
Mountain Research Project, showing unnormalized (at the top)
and normalized (at the bottom) counts for wndNW (annual northwest
wind counts at North Lookout), wndNNW (north-northwest wind
counts), and RT_All (annual counts of red-tailed hawks). The
dashed lines give 5-year running averages that smooth out the
peaks and valleys.
Figure 2: Unnormalized and normalized line graphs of wndNW,
wndNNW, and RT_All with 5-year averages
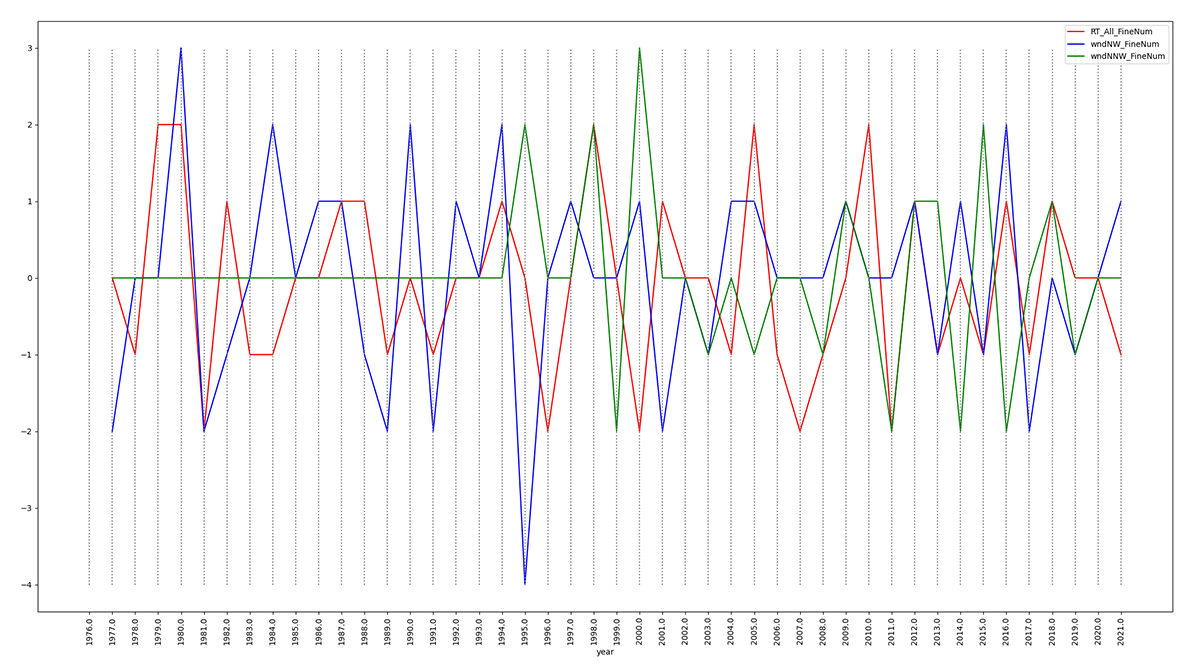
Figure 3: python plotcsv.py findPeaksValleys.csv year
RT_All_FineNum wndNW_FineNum wndNNW_FineNum
Figure 3 plots the output of script findPeaksValleys.py's _FineNum
extraction of these 3 attributes showing approximate alignment of
RT_All peaks and valleys to wndNW and wndNNW since about 2010.
File findPeaksValleys.csv is the output from your script findPeaksValleys.py.
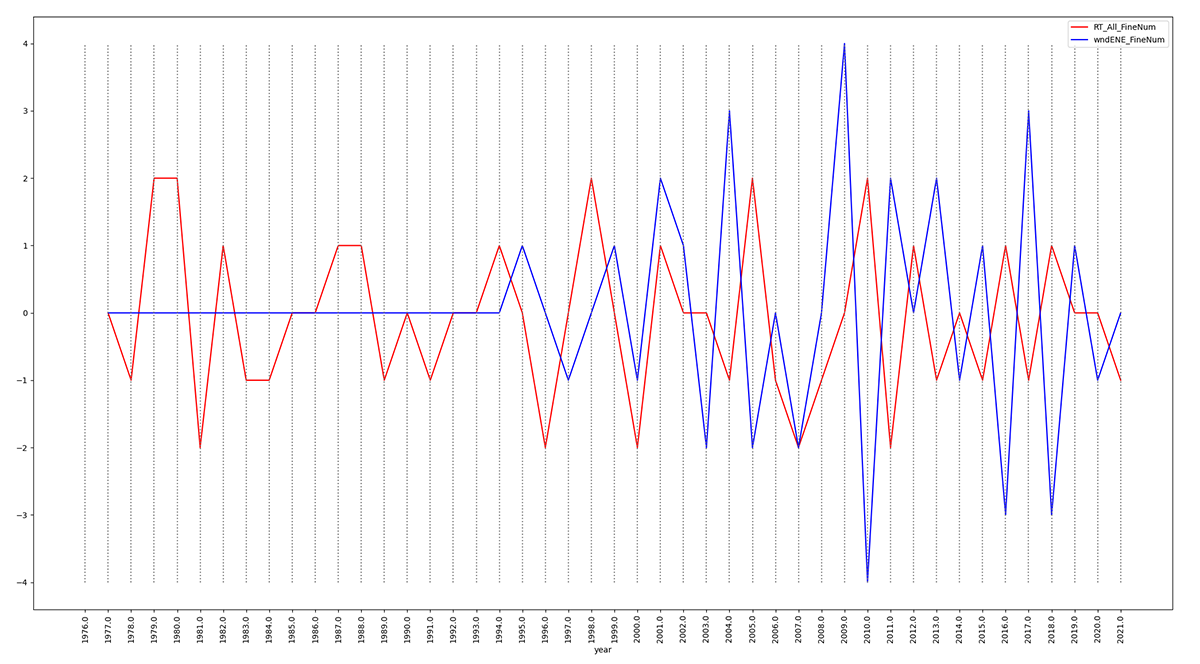
Figure 4 shows even tighter inverse (negative) correlation
of RT_All and wnd_ENE in recent years.
Figure 4: python plotcsv.py findPeaksValleys.csv year
RT_All_FineNum wndENE_FineNum
You can run plotcsv.py with the "-file" command line argument to
generate a PNG file that you can view immediately with a web
browser as follows.
$ python plotcsv.py findPeaksValleys.csv year -file
RT_All_FineNum wndENE_FineNum
DEBUG X TYPE <class 'float'> 1976.0
X is year Type is <class 'float'>
MEAN
1998.5 MEDIAN
1998.5 PSTDEV
13.275918047351754 MIN 197
6.0 MAX 2021.0
Y is wndENE_FineNum Type is <class 'float'>
BROWSE https://acad.kutztown.edu/~parson/plotcsv.png
For this to work you must have a login directory (~) and a
~/public_html directory with read and execute permissions enabled.
Here are mine as an example.
$ ls -ld ~
drwxr-xr-x. 26 parson apache 4096 Aug 26 13:26
/home/kutztown.edu/parson
$ ls -ld ~/public_html
drwxr-xr-x. 8 parson csit_faculty 20480 Aug 23 16:47
/home/kutztown.edu/parson/public_html
If you do not see the ~/public_html directory do this:
$ mkdir ~/public_html
If you do not see "r-x" in the bottom 3 permission characters do
this:
$ chmod o+r+x ~
$ chmod o+r+x ~/public_html
Check permissions again with the "ls" command per above
instructions.
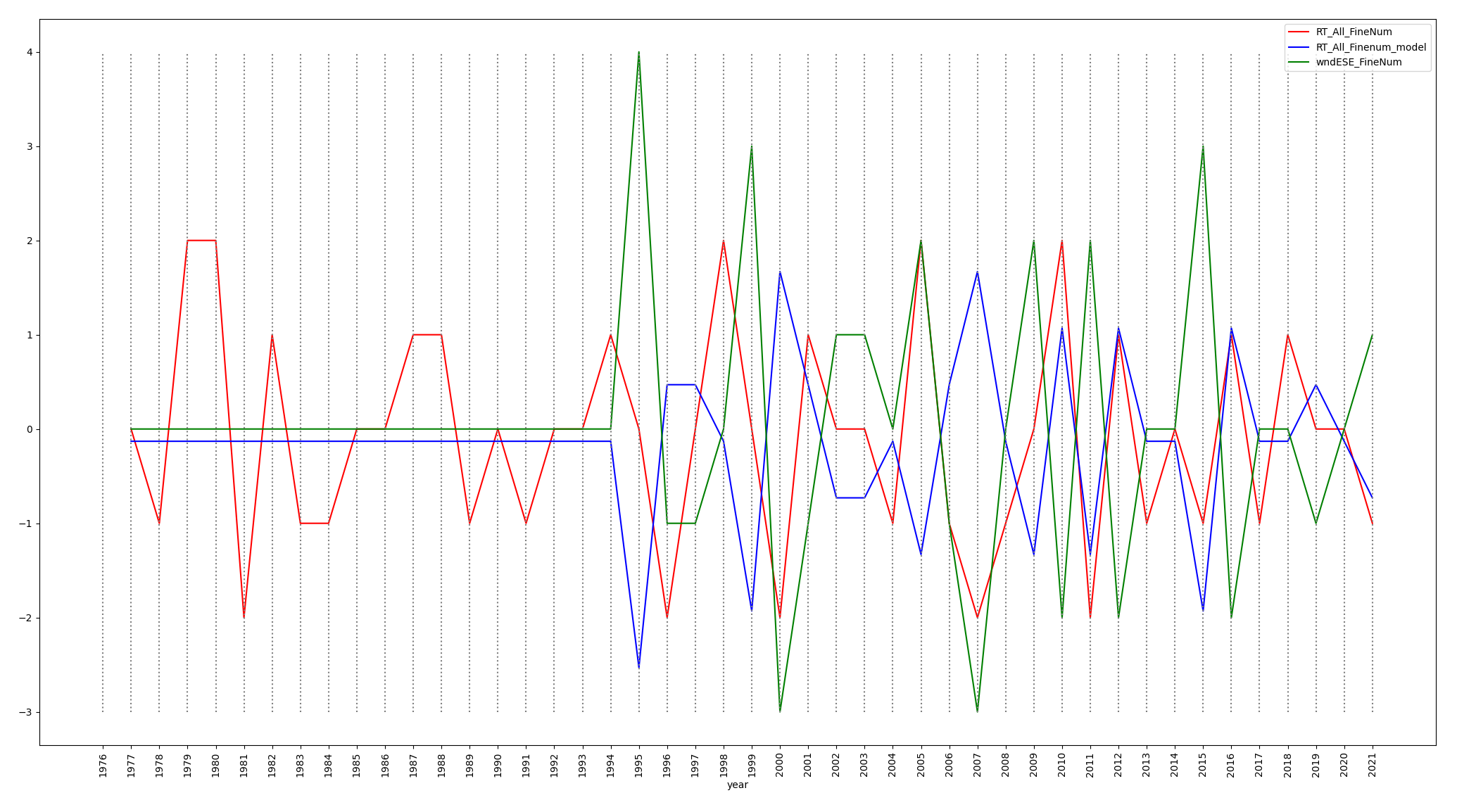
Here is another plot using wndESE_FineNum correlation to
RT_All_FineNum:
Figure 5: python plotcsv.py findPeaksValleys.csv year
RT_All_FineNum RT_All_Finenum_model wndESE_FineNum
The RT_All_Finenum_model is a fairly highly-accurate regression
model for 2010 through 2021 that we will discuss later.
Simple Linear regression on wndESE_FineNum for years 2010 thru
2021 RT_All_FineNum = -0.6 * wndESE_FineNum - 0.13
Predicting 0 if attribute value is missing.
Correlation
coefficient
0.7666
Mean absolute
error
0.5833
Root mean squared
error
0.7179
RT_All_FineNum range is [-2,2]
3. We will go over the handout code in class.
When you are ready to test your code, type make
clean test in the code directory. A successful
test run looks like this:
Tests can fail in one of two ways. Script findPeaksValleys.py may
blow up on a bug with an error message to the terminal, e.g., the
handout code bug above:
The findPeaksValleys.csv.dif file shows differences between output
file findPeaksValleys.csv and correct reference file
findPeaksValleys.csv.ref. You may need to use an editor to compare
the difference lines from findPeaksValleys.csv and
findPeaksValleys.csv.ref if findPeaksValleys.csv.dif is too hard
to interpret. I will demo a diff in class.
4. After make clean test works without
errors (terminates without an error message), type make
turnitin and hit Enter at the prompt to get your work to
me before the deadline.
If you make subsequent changes and make clean test still
passes, you can run make turnitin again and over-write
your previous submission. Note that this is not the "turnin"
script you may have used in other courses.
There is a 10% per day penalty for late assignments in my courses
and I cannot grant any points after I go over a solution.
Do you really want to send CSC458assn1SLOPESfall2022 to Professor
Parson?
Hit Enter to continue, control-C to abort.
/bin/bash -c "cd .. ; /bin/chmod 700
.
; \
/bin/tar cvf
./CSC458assn1SLOPESfall2022_parson.tar
CSC458assn1SLOPESfall2022 ; \
/bin/gzip
./CSC458assn1SLOPESfall2022_parson.tar
; \
/bin/chmod 666
./CSC458assn1SLOPESfall2022_parson.tar.gz
; \
/bin/mv
./CSC458assn1SLOPESfall2022_parson.tar.gz ~parson/incoming"
CSC458assn1SLOPESfall2022/
CSC458assn1SLOPESfall2022/year_aggregate_HMS_2013_2021.csv
CSC458assn1SLOPESfall2022/__pycache__/
CSC458assn1SLOPESfall2022/arfflib_3_2.py
CSC458assn1SLOPESfall2022/findPeaksValleys.csv.ref
CSC458assn1SLOPESfall2022/findPeaksValleys.py
CSC458assn1SLOPESfall2022/makelib
CSC458assn1SLOPESfall2022/plotcsv.py
CSC458assn1SLOPESfall2022/year_aggregate_HMS_1976_2021_kupapcsit01.csv
CSC458assn1SLOPESfall2022/makefile
*************************************** In [1]: # HINTS FOR STUDENT 2
In [2]: s = 'abCdeFChijClllll'
In [3]: s1 = s.replace('C','') # removes the Cs from a copy, '' is
two single quotes
In [4]: s1
Out[4]: 'abdeFhijlllll'
In [5]: s
Out[5]: 'abCdeFChijClllll'
In [6]: s.startswith('a')
Out[6]: True
In [7]: s.startswith('b')
Out[7]: False
In [8]: s2 = s[3:] # slice from 4th char (skip 0, 1, 2) thru the
end
In [9]: s2
Out[9]: 'deFChijClllll'
In [10]: s
Out[10]: 'abCdeFChijClllll'
In [11]: myset = set([])
In [12]: for character in s:
...:
myset.add(character)
...:
In [13]: print(myset) # no duplicates in a set
{'a', 'l', 'e', 'b', 'j', 'i', 'h', 'C', 'd', 'F'}
In [15]: mylist = list(myset) ; print(mylist)
['a', 'l', 'e', 'b', 'j', 'i', 'h', 'C', 'd', 'F']
In [16]: mylist.sort() ; print(mylist)
['C', 'F', 'a', 'b', 'd', 'e', 'h', 'i', 'j', 'l']
In [17]: mylist2 = sorted(myset) ; print(mylist2)
['C', 'F', 'a', 'b', 'd', 'e', 'h', 'i', 'j', 'l']
In [18]: # HINTS FOR STUDENT 3
In [19]: rowsOfData = [ # our datasets are rows of lists of fields
...: [colix + rowix for colix in range(0,9)]
...: for rowix in range(0,99,10)] # List comprehensions not needed for STUDENT 3. I need some
data to demo.
In [20]: rowsOfData
Out[20]:
[[0, 1, 2, 3, 4, 5, 6, 7, 8],
[10, 11, 12, 13, 14, 15, 16, 17, 18],
[20, 21, 22, 23, 24, 25, 26, 27, 28],
[30, 31, 32, 33, 34, 35, 36, 37, 38],
[40, 41, 42, 43, 44, 45, 46, 47, 48],
[50, 51, 52, 53, 54, 55, 56, 57, 58],
[60, 61, 62, 63, 64, 65, 66, 67, 68],
[70, 71, 72, 73, 74, 75, 76, 77, 78],
[80, 81, 82, 83, 84, 85, 86, 87, 88],
[90, 91, 92, 93, 94, 95, 96, 97, 98]]
In [23]: column2Sum = {}
In [24]: for col in range(0, len(rowsOfData[0])):
...: column2Sum[col] =
0
...:
In [25]: column2Sum
Out[25]: {0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0}
In [26]: for row in rowsOfData:
...: for col in
range(0, len(row)):
...:
column2Sum[col] = column2Sum[col] + row[col]
...:
In [27]: column2Sum
Out[27]: {0: 450, 1: 460, 2: 470, 3: 480, 4: 490, 5: 500, 6: 510,
7: 520, 8: 530
}
In [29]: sum(range(0,91,10)) # This is an error check for
validation of the above.
Out[29]: 450
In [31]: sum(range(8,99,10)) # Also validation.
Out[31]: 530
In [35]: # HINTS FOR STUDENT 4, just the set-related stuff
In [36]: myset
Out[36]: {'C', 'F', 'a', 'b', 'd', 'e', 'h', 'i', 'j', 'l'}
In [37]: 'b' in myset
Out[37]: True
In [38]: not 'b' in myset
Out[38]: False
In [39]: 'w' in myset
Out[39]: False
In [40]: not 'w' in myset
Out[40]: True
In [41]: v = None
In [42]: v in myset
Out[42]: False
In [43]: v == None
Out[43]: True
In [44]: v != None
Out[44]: False
In [45]: v = 'l'
In [46]: v in myset
Out[46]: True
In [35]: # HINTS FOR STUDENT 5, the key & set-related stuff
In [51]: column2Sum
Out[51]: {0: 450, 1: 460, 2: 470, 3: 480, 4: 490, 5: 500, 6: 510,
7: 520, 8: 530}
In [52]: column2Sum.keys()
Out[52]: dict_keys([0, 1, 2, 3, 4, 5, 6, 7, 8])
In [53]: myset
Out[53]: {'C', 'F', 'a', 'b', 'd', 'e', 'h', 'i', 'j', 'l'}
In [54]: for k in column2Sum.keys():
...: character =
chr(ord('a') + k)
...: # ord converts a
char to its integer represetntation
...: # chr converts
integer representation to a character
...: if not character
in myset:
...:
print('character',character,'missing from myset.')
...:
character c missing from myset.
character f missing from myset.
character g missing from myset.
In [60]: # HINTS FOR STUDENT 6, just the try-catch stuff
In [61]: somedata = [0, 1.1, -2, None, 'fred', '22', '-22.2',
None]
In [62]: numdata = []
In [63]: for element in somedata:
...: try:
...: value =
float(element)
...: except Exception:
...: value = None
...:
numdata.append(value)
...:
In [64]: numdata
Out[64]: [0.0, 1.1, -2.0, None, None, 22.0, -22.2, None]