CSC 458 - Data
Mining & Predictive Analytics I, Fall 2022, Assignment 3
on Data Compression & Classification.
Assignment 3 due 11:59 PM Thursday November 3 via D2L
Assignment 3. You can do this on any machine with Weka
installed.
The October 18 class will walk through this handout with any
remaining time available for project work.
Q1
through Q11 in
README.assn3.txt
are worth 8%
each and a
correct CSC458assn3.arff.gz file is worth 12%. There is a
10% penalty for each day it is late to D2L.
1. To get the assignment:
Download compressed ARFF data file month_HM_reduced_aggregate.arff.gz
and Q&A file README.assn3.txt from these
links.
You must answer questions in README.assn3.txt and save
& later turn in working file CSC458assn3.arff.gz.
Each answer for Q1 through Q11 in README.assn3.txt is worth 8
points, and CSC458assn3.arff.gz
with correct contents is worth 12%, totaling 100%. There is a 10%
late penalty for each day the assignment is late.
2. Weka and README.assn3.txt operations
Start Weka, bring up the Explorer GUI, and open
month_HM_reduced_aggregate.arff.gz.
Set Files of Type at the bottom of the
Open window to (*.arff.gz) to see the input ARFF file. Double
click it.
This ARFF file has 45 attributes (columns) and 226 instances
(rows) of monthly aggregate data from August through December of
1976 through 2021.
Here are the attributes in the file. It is a
monthly aggregate of daily aggregates of (mostly 1-hour)
observation periods.
year
1976-2021
month
8-12
HMtempC_mean
mean for month of temp Celsius during observation times
WindSpd_mean
same for wind speed in km/hour
HMtempC_median
median for month
WindSpd_median
HMtempC_pstdv
population standard deviation
WindSpd_pstdv
HMtempC_min
minimum & maximum
WindSpd_min
HMtempC_max
WindSpd_max
wndN
tally of North winds for all observations in the month, etc.
wndNNE
wndNE
wndENE
wndE
wndESE
wndSE
wndSSE
wndS
wndSSW
wndSW
wndWSW
wndW
wndWNW
wndNW
wndNNW
wndUNK
HMtempC_24_mean
Changes in magnitude (absolute value of change) over 24, 48, and
72 hours
HMtempC_48_mean
HMtempC_72_mean
HMtempC_24_median
HMtempC_48_median
HMtempC_72_median
HMtempC_24_pstdv
HMtempC_48_pstdv
HMtempC_72_pstdv
HMtempC_24_min
The min & max are their signed values.
HMtempC_48_min
HMtempC_72_min
HMtempC_24_max
HMtempC_48_max
HMtempC_72_max
SS_All
Tally of sharp-shinned hawk observations during each month 8-12,
1976-2021. Target attribute.
You can examine its contents and sort based on attributes by
opening the file in the Preprocess Edit button.
2a. In the Preprocess tab open Filter -> unsupervised ->
attribute -> AddExpression and add the following 4 derived
attributes.
Enter name
SS_All_Range10 with an expression aN, where N is
the attribute number of SS_All, which is our primary target
attribute. (Use a45 for attribute 45, not "45" or "aN".) Apply.
Be careful NOT TO
INCLUDE SPACES within your derived attribute names.
Enter name SS_All_EqFreq10
with an expression aN, where N is again the attribute
number of SS_All. Apply.
Enter name SS_All_Sqrt with
an expression sqrt(aN), where N is the attribute
number of SS_All. Apply.
This step compresses the
SS_All tally.
Enter name SS_All_Log10 with
an expression log(aN+1)/log(10), where N is the
attribute number of SS_All. Apply.
This step compresses
SS_All even more.
The reason for adding +1
to aN is to avoid taking the log(0) for SS_All counts of 0,
which is undefined. None will be negative.
At this point you have 49 attributes.
2b. Select Filter -> unsupervised -> attribute ->
Discretize to chop SS_All_Range10 and SS_All_EqFreq10 into 10
discrete classes as follows.
Set the Discretize attributeIndices
to the index of SS_All_Range10, leave the other
Discretize parameters at their defaults (useEqualFrequency is
False), and Apply.
Set the Discretize attributeIndices
to the index of SS_All_EqFreq10, set useEqualFrequency
to True, leave the other Discretize parameters at their
defaults, and Apply.
Save this dataset as CSC458assn3.arff.gz,
making sure "Files of Type" is set to (*.arff.gz) and the file
is named correctly. It has 49 attributes.Turn in CSC458assn3.arff.gz
when your turn in your README.assn3.txt to D2L.
Figures 1 through 5 show the statistical distributions of SS_All
and these 4 derived attributes. Use the Preprocessor to make
sure yours look the same.
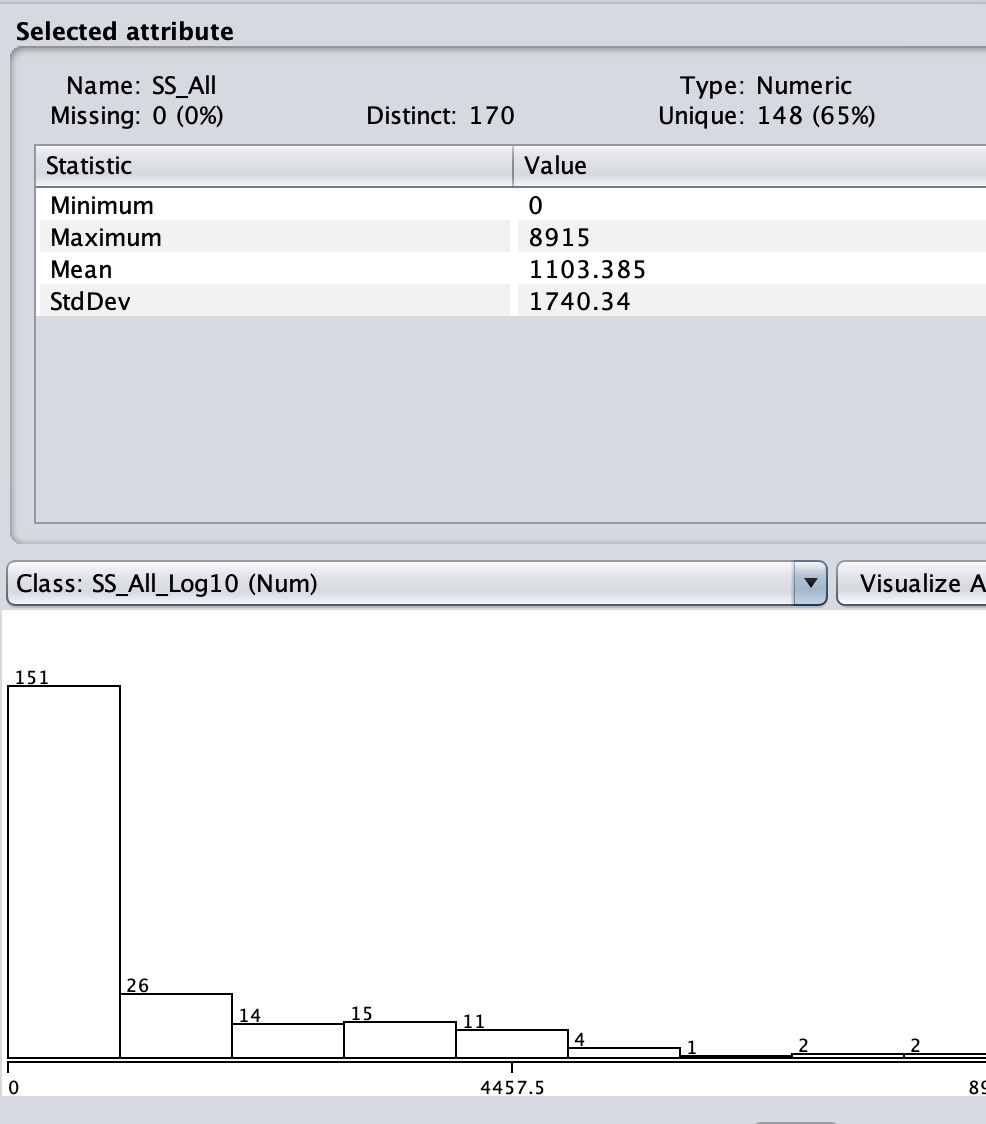
Figure 1: SS_All
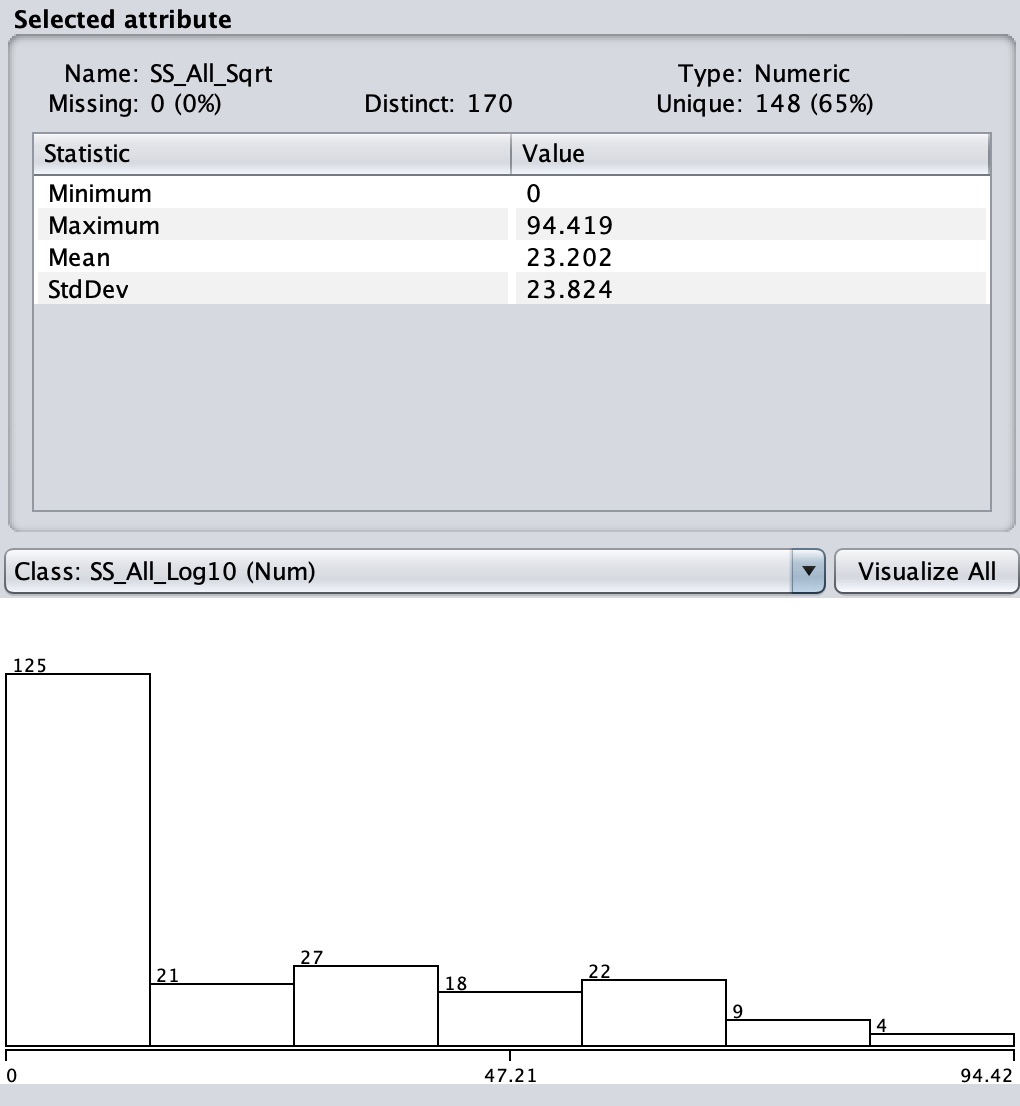
Figure 2: SS_All_Sqrt
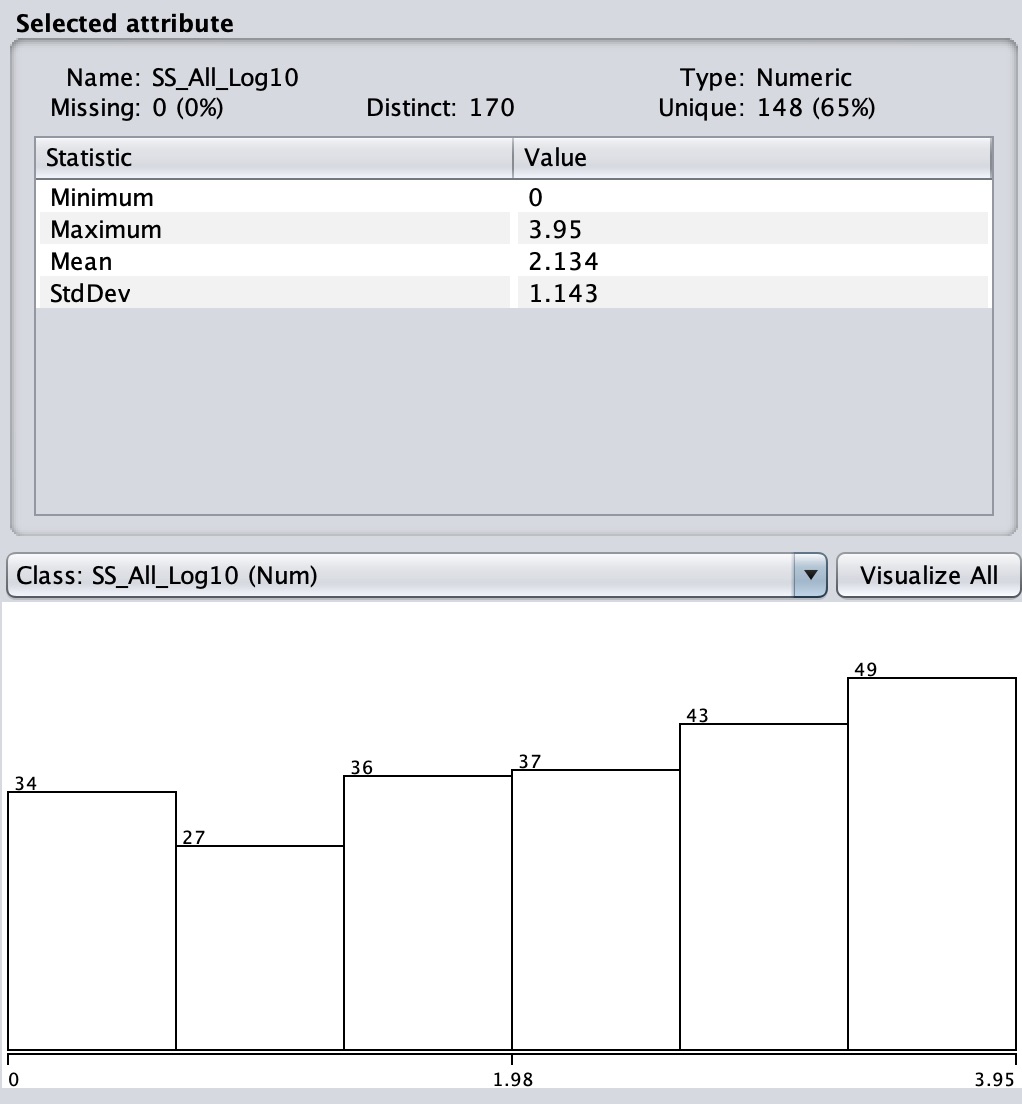
Figure 3: SS_All_Log10
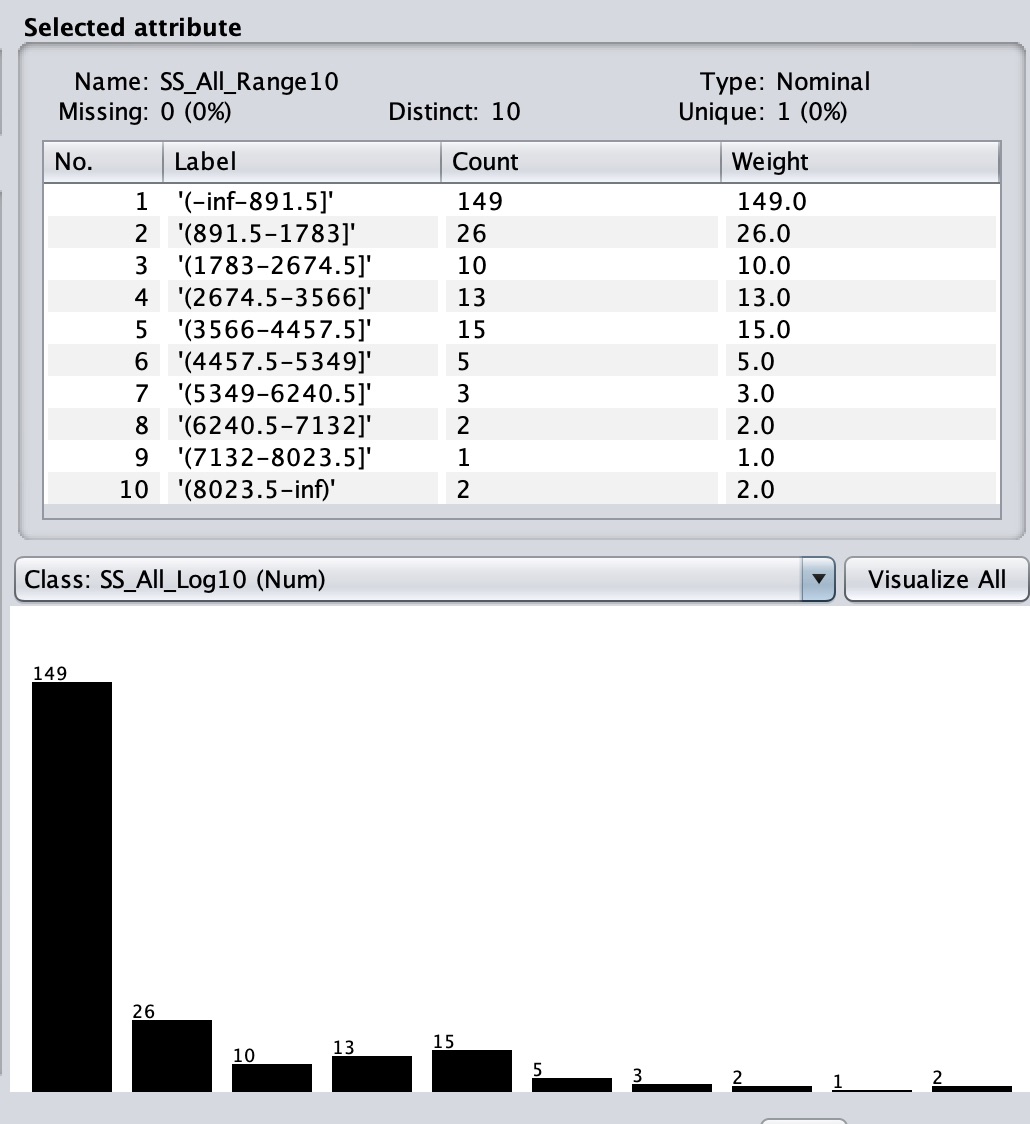
Figure 4: SS_All_Range10 (may be filled with white instead of
black)
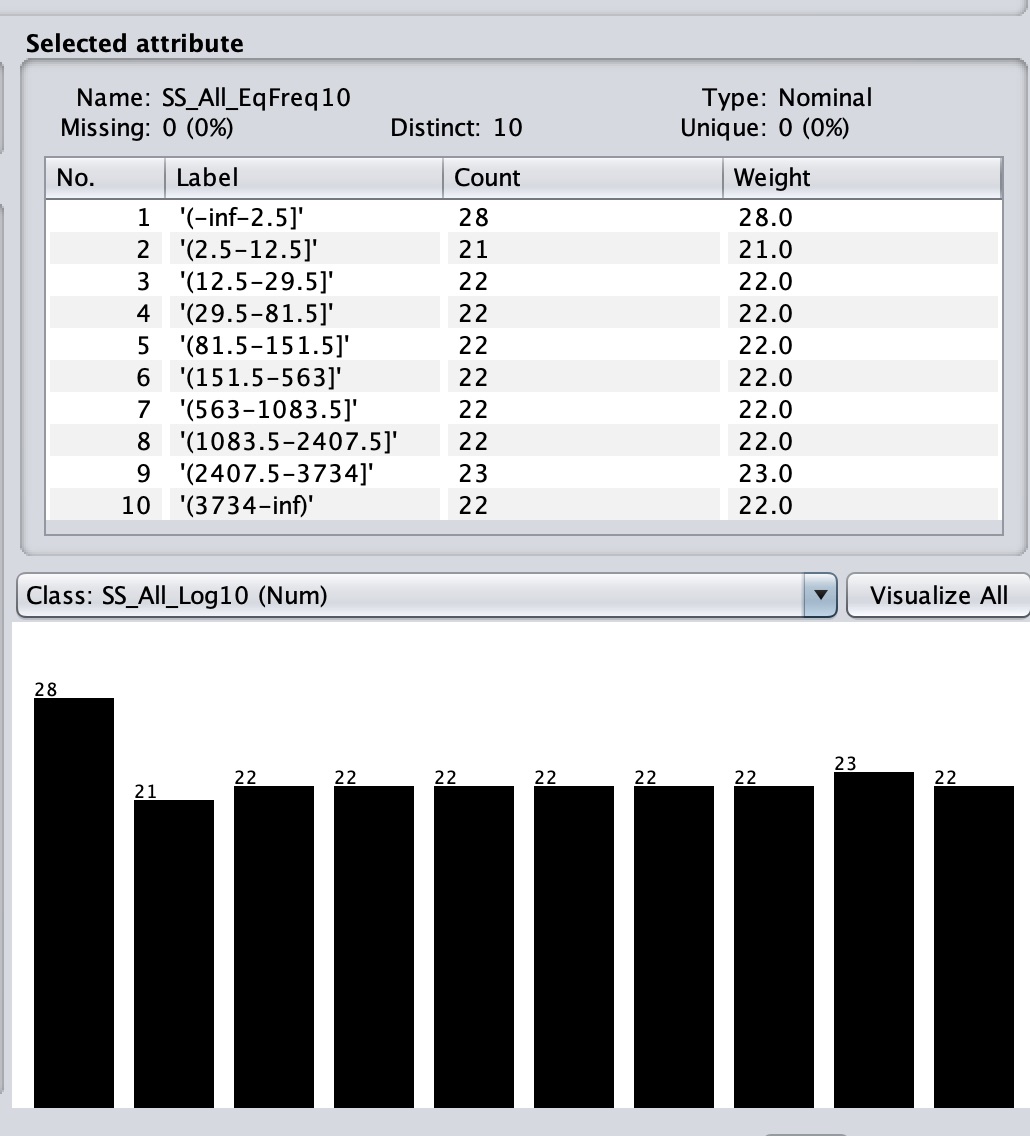
Figure 5: SS_All_EqFreq10
Check to sure that your distributions match Figures 1 through
5.
2c. Remove derived
attributes SS_All_Range10, SS_All_EqFreq10, SS_All_Sqrt,
and SS_All_Log10 so that SS_All is the only target
attribute, following non-target attribute HMtempC_72_max. We will
use them later.
REGRESSION:
Q1: In the Classify TAB run rules -> ZeroR and fill in
these numbers N.N below by sweeping the output with your mouse,
hitting control-C to copy, and then pasting into README.assn3.txt,
just like Assignment 2. What accounts for the predicted
value of ZeroR? Examine the statistical properties of
SS_All in the Preprocess tab to find the answer.
ZeroR predicts class value: N.N (This is the predicted
value of ZeroR.)
Correlation
coefficient
N.N
Mean absolute
error
N.N
Root mean squared
error
N.N
Relative absolute
error
N %
Root relative squared
error
N %
Total Number of
Instances
226
Q2: In the Classify
TAB run functions -> LinearRegression and
fill in these numbers N.N below.
Correlation
coefficient
N.N
Mean absolute
error
N.N
Root mean squared
error
N.N
Relative absolute
error
N %
Root relative squared
error
N %
Total Number of
Instances
226
Q3: In the Classify TAB run
trees -> M5P and fill in these
numbers N.N below.
Correlation
coefficient
N.N
Mean absolute
error
N.N
Root mean squared
error
N.N
Relative absolute
error
N %
Root relative squared
error
N %
Total Number of
Instances
226
Q4: In the M5P model tree of Q3, how many Rules (linear
expressions) are there? Also, in the decision tree that
precedes the first leaf linear expression "LM num: 1", what
attributes are the key decision tree attributes in predicting
SS_All? Copy & paste this section of the Weka output (the
decision tree), and then list the attributes in the tree to
ensure you see them all.
M5 pruned model tree:
(using smoothed linear models)
Paste the decision tree that appears here in Weka's
output.
LM num: 1
Q5: In the decision tree of Q4, the leaf nodes that point to
linear expressions look like this:
| | | |
ATTRIBUTE_NAME <= N.N : LM4 (13/26.17%)
In that leaf, 13 is the COUNT of the total 226
observation instances reaching that decision, 26.17% is
an Error Measure (the root relative squared
error just for that leaf, with 0.0% being the least and
100.0% being the worst error rate. LM4 in this example
is the linear expression below.
What month or months have the lowest Error Measure (the root
relative squared error) in Q4's decision
tree? Why do you think that is? Take a look
at Figure 27 near the bottom of this section
of the Hawk Mountain ongoing analysis.
https://acad.kutztown.edu/~parson/HawkMtnDaleParson2022/#SS
"